Oracle
- Script d'audit de base ORACLE
- Oracle - Problèmes divers et solutions
- Intégrer des données UTF8 avec sqlplus
- logrotate alert.log
- OUI 19c - page d'accueil vide
- Purge des traces
- Recreate DBConsole
- Récupérer les touches de direction et l'historique dans sqlplus linux
- Services SYSTEMD base et listener
- switch user ("su" like)
- Erreur ORA-00600 - index, ou blocs, ou lob corrompu
- Erreur RMAN-03014 après upgrade d'une base RMAN
- Erreurs en connexion SYSDBA sous windows
- RMAN duplicate erreur "ORA-01843"
- Vérifier les possibilités de réduction des tablespaces
- Oracle 19 - impossible de créer le LISTENER
- Oracle linux - l'utilisateur oracle ne voit pas le listener lancé par SYSTEMD
- Analyse de toutes les tables et/ou des indexes
- ASM - Automatic Storage Management - Tips&Tricks
- ASM - Déplacement d'une base complète à froid
- AWR (AUTOMATIC WORKLOAD REPOSITORY) - Tips&Tricks
- AWR remplit le tablespace SYSAUX
- Calculer la mémoire totale utilisée par une base
- Catalogue RMAN centralisé
- Déplacement d'une base complète vers un nouveau serveur avec changement du chemin des fichiers
- Déplacer les fichiers d'une base
- Déplacer un LOB dans un autre tablespace
- Déplacer une base vers un nouveau serveur en changeant les chemins des fichiers
- Duplication par RMAN avec changement de SID, et de chemin des fichiers.
- expdp COHERENT (flashback_scn ou flashback_time)
- Forcer sqlplus en sysdba sur une base morte
- Full upgrade 11g -> 19c après transfert des fichiers
- Gestion des JOBs
- HA niveau 1 : Failover database sur Standard Edition
- HA niveau 2 - Oracle 11g Cross platform Active Standby - Windows Primary database and Linux Active Standby
- HA niveau 2 - Standby database logical from physical with RMAN from active database
- HA niveau 2 - Standby database manuelle (cold) sur Standard Edition (linux)
- HA niveau 2 - Standby database manuelle (cold) sur Windows - Std Edition (services et tâches planifiées)
- HA niveau 2 - Standby database manuelle par RMAN (hot) sur Standard Edition
- HA niveau 3 - Standby DataGuard database sur 11g Enterprise Edition
- HA niveau 4 - RAC database 10g sur Enterprise Edition
- impdp dblink - Importer des données sans export préalable
- Import de schémas utilisateurs
- LISTENER : enregistrement automatique des bases
- Migration par transport tablespace
- Mode ARCHIVELOG
- NLS LANG et nls_*_parameters et SQLPLUS en UTF8
- Oracle 11gR2 sur RedHat 7 64 bits
- REBUILD de tous les indexes
- Reconstruire la DBconsole sur Oracle 10g
- Réduction/augmentation des REDO LOGs
- Remplacement/resize d'un tablespace UNDO
- Remplacement/resize d'un tablespace TEMP
- RMAN - scripts standards
- Simuler "SU" sous sqlplus
- Suppression de JOB Oracle 10g
- Supprimer tous les objets d'un utilisateur en une seule fois
- Trace SQL sur session utilisateur
- Trouver ce qui charge le CPU
- Trouver les requêtes longues
- Upgrade manuel (version <= 11.2.0)
- Upgrade mineur Oracle 11g
- Utilisation de EXPLAIN PLAN
- Vider automatiquement la corbeille RECYCLE_BIN
- Voir les requêtes courantes, longues, les conflits, les verrous
- Mise à jour avec nettoyage des patchs
Script d'audit de base ORACLE
Dernière version :
https://github.com/fsoyer/auditOracleHTML
Oracle - Problèmes divers et solutions
Diverses astuces
Intégrer des données UTF8 avec sqlplus
La base doit être en UTF8.
Forcer l'environnement du client sqlplus. Avant de la lancer :
set (ou export) NLS_LANG=_.UTF8logrotate alert.log
A ajouter dans /etc/logrotate.d/alert_orcl
#alert log base ORCL
/oracle/ora11g/diag/rdbms/orcl/ORCL/trace/alert_ORCL.log {
monthly
rotate 3
notifempty
missingok
copytruncate
nocreate
compress
}OUI 19c - page d'accueil vide
Lorsqu'on lance OUI (runInstaller) à partir d'un serveur Linux (exemple : Rocky linux 8) via ssh et X forwarding, si la page n'affiche aucun contenu :
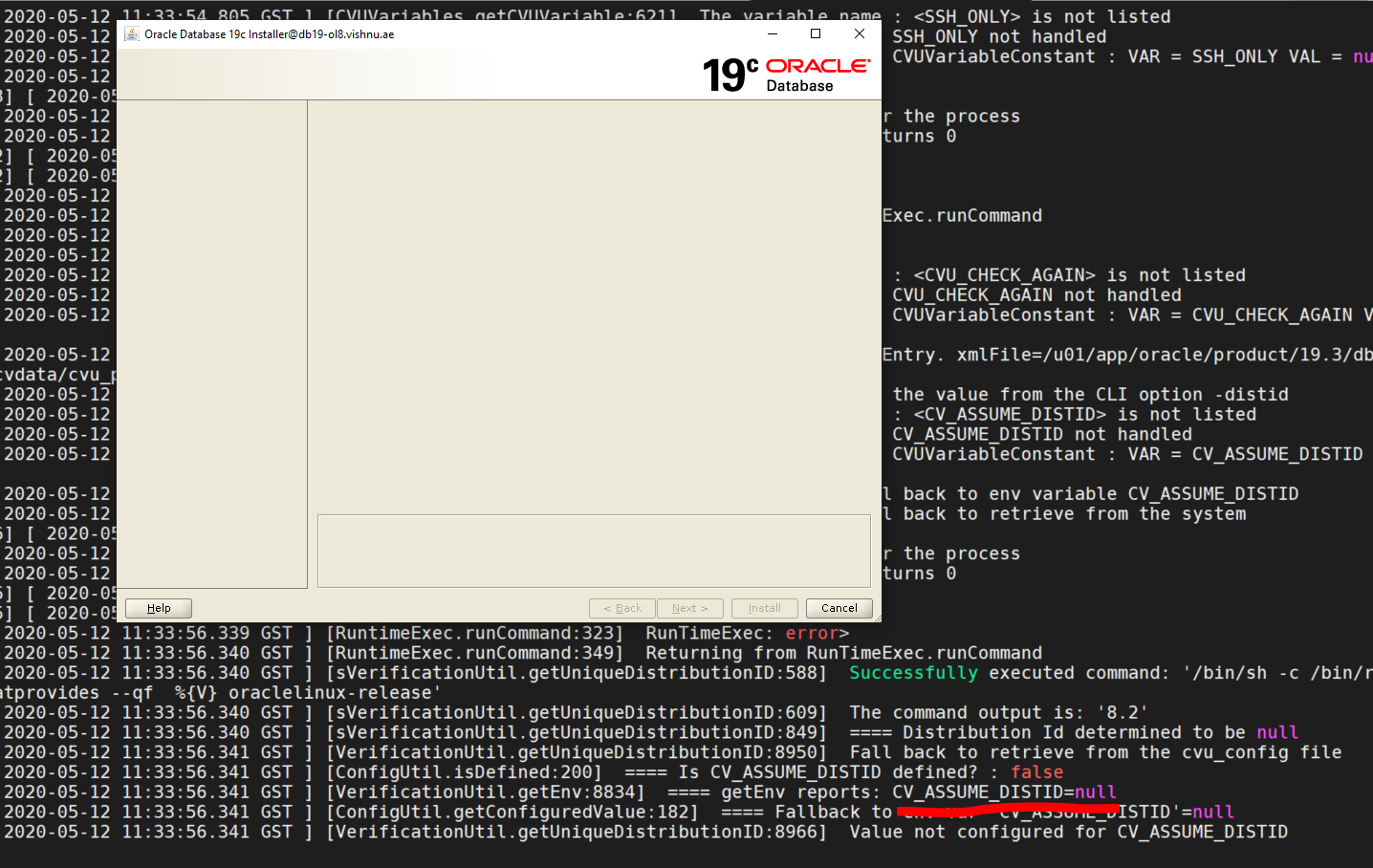
On peut démarrer runInstaller avec l'option "-debug". On voit alors (ici sur l'image) qu'il y a un problème avec CV_ASSUME_DISTID. Effectivement, cette installation est faite sur une distribution Rocky 8, le problème ici n'est pas "Rocky" mais "8".
On commence donc par vérifier la version exacte
$ cat /etc/redhat-release
Rocky Linux release 8.8 (Green Obsidian)Et on lance runIstaller en initialisant la variable
$ CV_ASSUME_DISTID=8.8 ./runInstaller Purge des traces
A planifier en CRONTAB
#!/bin/sh
export ORACLE_HOME=/oracle/ora11g/dbhome
/oracle/ora11g/dbhome/bin/adrci exec = "show home"|awk '{if (NR >= 2) print $1}'|while read rep_diag
do
echo "purge de $rep_diag";date
/oracle/ora11g/dbhome/bin/adrci exec = "set home $rep_diag;purge -age 10080"
done
find /oracle/ora11g/dbhome/rdbms/audit -mtime +90 -exec rm -f {} \;
exit 0Recreate DBConsole
Initialiser ORACLE_HOSTNAME avec le FQDN EXACT du serveur
Initialiser ORACLE_SID (mais peut-être pas nécessaire? A vérifier)
set ORACLE_SID=MYDB
set ORACLE_HOSTNAME=oraclehost.local
emca -config dbcontrol db -repos recreateRépondre aux questions (port listener = 1521, password des users ORACLE sys, system,dbsnmp et sysman)
A la fin, si erreur de sécurisation (le https n'a pas pu être généré), tenter :
emctl stop dbconsole
emctl config emkey -repos -sysman_pwd <mot-de-passe-SYSMAN>
emctl secure dbconsole -sysman_pwd <mot-de-passe-SYSMAN>
emctl stop dbconsolemais ça ne fonctionne pas forcément... Dans ce cas, la console reste accessible en http "simple".
Vérifier qu'elle tourne :
export ORACLE_SID=nom_de_l_instance
export ORACLE_UNQNAME=nom_unique_de_la_base
emctl status dbconsoleRécupérer les touches de direction et l'historique dans sqlplus linux
Installer rlwrap
lancer sqlplus par :
rlwrap sqlplus user/passwordsi le client est en version 10g XE, on peut aussi modifier /usr/lib/oracle/xe/app/oracle/product/10.2.0/client/scripts/sqlplus.sh
Services SYSTEMD base et listener
Vérifier dans /etc/oratab que la base est listée et est à "Y" car dbstart/dbshut s'appuient dessus.
Environnement (/etc/sysconfig/env.orcl):
ORACLE_BASE=/opt/oracle/
ORACLE_HOME=/opt/oracle/product/12.2.0/db_1
ORACLE_SID=ORCL
ORACLE_USER=oracle
ORACLE_GROUP=oinstall
ORACLE_LISTENER=LSN_ORCLService systemd de démarrage de la base (ex : /usr/lib/systemd/system/oracleORCL.service) :
[Unit]
Description=Oracle databases service
Before=shutdown.target multi-user.target
After=opt-oracle.mount
[Service]
Type=forking
EnvironmentFile=/etc/sysconfig/env.orcl
User=$ORACLE_USER
Group=$ORACLE_GROUP
ExecStart=$ORACLE_HOME/bin/dbstart $ORACLE_HOME &
ExecStop=$ORACLE_HOME/bin/dbshut $ORACLE_HOME
[Install]
WantedBy=multi-user.targetService systemd de démarrage du listener (ex : /usr/lib/systemd/system/listener.service) :
[Unit]
Description=Oracle listener
After=network.target
[Service]
RemainAfterExit=yes
EnvironmentFile=/etc/sysconfig/env.orcl
ExecStart=$ORACLE_HOME/bin/lsnrctl start $ORACLE_LISTENER &
ExecStop=$ORACLE_HOME/bin/lsnrctl start $ORACLE_LISTENER
[Install]
WantedBy=multi-user.targetswitch user ("su" like)
Créer un script "su.sql" :
whenever sqlerror exit
column password new_value pw
-- test access to dba_users and if the user exists
declare
l_passwd varchar2(45);
begin
select password into l_passwd
from sys.dba_users
where username = upper('&1');
end;
/
-- select password in variable pw
select password
from sys.dba_users
where username = upper( '&1' );
/
-- change the password for "Hello"
alter user &1 identified by Hello;
connect &1/hello
-- once connected, change password back
alter user &1 identified by values '&pw';
show user
whenever sqlerror continueErreur ORA-00600 - index, ou blocs, ou lob corrompu
On trouve des erreurs ORA-0600 dans l'alert.log. Il peut s'agir de blocs disque corrompus suite à un problème d'accès disque, ou d'un index désynchronisé, ou d'un LOB corrompu dans la table (liste non exhaustive !).
ORA-00600: internal error code, arguments: [13011], [117675], [32437212], [0], [32705125], [0], [], [], [], [], [], []
NOTE : il existe un décodeur d'ORA-00600 sur Metalink :
https://metalink.oracle.com/metalink/plsql/ml2_documents.showDocument?p_database_id=NOT&p_id=153788.1
NOTE 2 : Si l'erreur ORA-00600 ne génère pas des codes décodables, en général le fichier trace associé à l'erreur 0600 permet de trouver la requête, donc la table, affectée.
Trouver la table concernée par le bloc corrompu
Trouver le fichier et la table concernée (voir FIX ORA-00600 (1) pour la liste des paramètres de l'erreur 0600):
SELECT owner, object_name, object_type, object_id, data_object_id
FROM dba_objects
WHERE data_object_id = 117675;ANALYZE et VALIDATE STRUCTURE
D'abord analyser la table :
analyze table myschema.mytable validate structure cascade;L'analyse de la table ne renvoie pas d'erreur
Si la commande ne renvoie pas d'erreur (00600), il faut faire de même avec ses indexes. Pour trouver les indexes :
select index_name from dba_indexes where owner='MYSCHEMA' and tble_name='MYTABLE';Puis, pour chaque index trouvé, valider la structure :
analyze index MYSCHEMA.<MYTABLE_IND1> validate structure;Si la table a trop d'index, on peut essayer de trouver lequel a un problème par :
SQL> alter session set max_dump_file_size = unlimited;
SQL> ALTER SESSION SET tracefile_identifier = 'mon_fichier_trace';
SQL> analyze table MYSCHEMA."MYTABLE" validate structure cascade into invalid_rows;Dans 'mon_fichier_trace', on trouve une ligne de ce type :
row not found in index tsn: 1 rdba: 0x00817bfa
On recherche l'index correspondant à "00817bfa" :
SELECT owner, segment_name, segment_type, partition_name
FROM DBA_SEGMENTS
WHERE header_file = (SELECT file#
FROM v$datafile
WHERE rfile# =
dbms_utility.data_block_address_file(
to_number('00817bfa','XXXXXXXX'))
AND ts#= 1)
AND header_block = dbms_utility.data_block_address_block(
to_number('00817bfa','XXXXXXXX'));Sinon, on peut essayer de générer un script pour les analyser tous :
select 'analyze index '||owner||'.'||index_name||' validate structure' from dba_indexes where owner='MYSCHEMA' and table_name='MYTABLE';L'analyse de la table renvoie des erreurs ORA-00600 ou ORA-01499 (échec de référence croisée à la table/index - voir fichier de trace)
SQL> analyze table myschema.mytable validate structure cascade;
analyze table myschema.mytable validate structure cascade
*
ERROR at line 1:
ORA-01499: table/index cross reference failure - see trace filela première chose à faire est de valider (par DB Verify : utilitaire "dbv") que ce n'était pas un problème physique sur le fichier du tablespace. Trouver le tablespace et le fichier contenant la table :
SQL> select tablespace_name from dba_tables where table_name='MYTABLE';
TABLESPACE_NAME
------------------------------
MYTBLSPCE
SQL> select file_name from dba_data_files where tablespace_name='MYTBLSPCE';
FILE_NAME
---------------------------------
/u01/ORADATA/MYDB/MYTBLSPCE01.DBF
SQL> show parameter db_block_size
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_block_size integer 8192Lancer dbv :
$ dbv file='MYTBLSPCE01.DBF' blocksize='8192'
DBVERIFY: Release 11.2.0.4.0 - Production on Fri Apr 26 16:35:54 2019
Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved.
DBVERIFY - Verification starting : FILE = /u01/ORADATA/MYDB/MYTBLSPCE01.DBF
DBVERIFY - Verification complete
Total Pages Examined : 3440640
Total Pages Processed (Data) : 3102612
Total Pages Failing (Data) : 0
Total Pages Processed (Index): 320
Total Pages Failing (Index): 0
Total Pages Processed (Other): 139223
Total Pages Processed (Seg) : 0
Total Pages Failing (Seg) : 0
Total Pages Empty : 198485
Total Pages Marked Corrupt : 0
Total Pages Influx : 0
Total Pages Encrypted : 0
Highest block SCN : 2784020020 (1.2784020020)Ici analyse sans erreur, ce n'est donc pas une erreur physique, mais bien une désynchronisation d'un index ou un lob corrompu. On reconstruit donc les indexes.
Si dbv renvoie des erreurs, le fichier lui-même est physiquement corrompu sur disque ! Il n'y a alors pas d'autre moyen que de re-créer la base proprement sur un disque valide et réimporter la dernière sauvegarde viable.
Reconstruction des indexes
SQL> ALTER INDEX "MYSCHEMA"."MYTABLE_IND1" REBUILD;
Index altered.Cependant, il peut arriver que le REBUILD ne suffise pas; où qu'on décide de recréer les index dans un autre tablespace par sécurité.
Re-création des indexes
SQL> set long 200000 pagesize 0
SQL> select dbms_metadata.get_ddl('INDEX','MYTABLE_IND1','MYSCHEMA') from dual;
DBMS_METADATA.GET_DDL('INDEX','MYTABLE_IND1','MYSCHEMA')
-------------------------------------------------------------------------------
CREATE INDEX "MYSCHEMA"."MYTABLE_IND1" ON "MYSCHEMA"."MYTABLE" ("COL1")
PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1
BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "MYTBLSPCE"
SQL> ALTER INDEX "MYSCHEMA"."MYTABLE_IND1" UNUSABLE;
Index altered.
SQL> DROP INDEX "MYSCHEMA"."MYTABLE_IND1";
Index dropped.
SQL> CREATE INDEX "MYSCHEMA"."MYTABLE_IND1" ON "MYSCHEMA"."MYTABLE" ("COL1")
Index created.Si l'index ne peut pas être recréé; exemple :
SQL> drop index "MYSCHEMA"."MYTABLE_IND1";
drop index "MYSCHEMA"."MYTABLE_IND1"
*
ERROR at line 1:
ORA-02429: cannot drop index used for enforcement of unique/primary keyalors il faut le reconstruire avec REBUILD, en espérant que ça suffira; ou le déplacer (il sera reconstruit par Oracle à la destination).
LOB : déplacer le LOB dans un autre tablespace
Si les indexes sont reconstruits sans erreurs mais que la table continue à générer des erreurs, et qu'elle contient des colonnes LOB, il peut s'agir d'un LOB corrompu. Dans ce cas, déplacer le LOB pour le reconstruire (voir Déplacer un LOB dans un autre tablespace)
Dernier recours : dupliquer la table en excluant les blocs corrompus
Le code suivant permet de dupliquer la table "tab1" vers une table "tab1_new" sans les lignes illisibles :
REM Create a new table based on the table that is producing errors with no rows:
create table MYSCHEMA.MYTABLE_NEW
as
select *
from MYSCHEMA.MYTABLE -- eventually, can add : "partition(<PARTITION_NUM>)"
where 1=2;
REM Create the table "bad_rows" to keep track of ROWIDs pointing to affected rows:
create table bad_rows (row_id rowid
,oracle_error_code number);
set serveroutput on
DECLARE
TYPE RowIDTab IS TABLE OF ROWID INDEX BY BINARY_INTEGER;
CURSOR c1 IS select /*+ index(tab1) */ rowid
from MYSCHEMA.MYTABLE tab1 -- eventually, can add : "partition(<PARTITION_NUM>)"
-- eventually add a filter to exclude others not necessary rows. Ex : where IMEI is NOT NULL;
;
r RowIDTab;
rows NATURAL := 20000;
bad_rows number := 0 ;
errors number;
error_code number;
myrowid rowid;
BEGIN
OPEN c1;
LOOP
FETCH c1 BULK COLLECT INTO r LIMIT rows;
EXIT WHEN r.count=0;
BEGIN
FORALL i IN r.FIRST..r.LAST SAVE EXCEPTIONS
insert into MYSCHEMA.MYTABLE_NEW
select /*+ ROWID(A) */ *
from MYSCHEMA.MYTABLE A -- eventually, can add : "partition(<PARTITION_NUM>)"
where rowid = r(i);
EXCEPTION
when OTHERS then
BEGIN
errors := SQL%BULK_EXCEPTIONS.COUNT;
FOR err1 IN 1..errors LOOP
error_code := SQL%BULK_EXCEPTIONS(err1).ERROR_CODE;
if error_code in (1410, 8103, 1578) then
myrowid := r(SQL%BULK_EXCEPTIONS(err1).ERROR_INDEX);
bad_rows := bad_rows + 1;
insert into bad_rows values(myrowid, error_code);
else
raise;
end if;
END LOOP;
END;
END;
commit;
END LOOP;
commit;
CLOSE c1;
dbms_output.put_line('Total Bad Rows: '||bad_rows);
END;
/Ressources
FIX ORA-0600 (1) : http://dmbadi.blogspot.com/2019/06/how-to-fix-ora-600-12700-internal-error.html
FIX ORA-0600 (2) : https://oracle-base.com/articles/misc/detect-and-correct-corruption
DBMS_REPAIR : https://www.jobacle.nl/?p=746
DUMP_ORPHAN_KEYS, SKIP_CORRUPT_BLOCKS : http://www.dba-oracle.com/concepts/dump_orphan_keys.htm
DBMS_REPAIR.FIX_CORRUPT_BLOCK : http://www.dba-oracle.com/t_fix_corrupt_blocks.htm
DB_ULTRA_SAFE, DB_BLOCK_CHECK* : http://www.dba-oracle.com/t_db_block_checking.htm
TOUT + DBV : http://www.datadisk.co.uk/html_docs/oracle/db_corruption.htm
Erreur RMAN-03014 après upgrade d'une base RMAN
PROBLEME :
La base RMAN a été upgradée de 11.2.0.2 en 11.2.0.4. La base elle-même a subit un "startup upgrade"+upgrade, et redémarrage, mais lors des sauvegardes on a l'erreur :
The database reported error while performing requested operation.
SBT_LIBRARY=/opt/omni/lib/libob2oracle8_64bit.so
CHILDERROR:1
Process exit code: 1, Signal: 0
RMAN PID=21788
APPERROR:
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: failure of allocate command at 03/13/2019 19:52:30
RMAN-03014: implicit resync of recovery catalog failed
RMAN-03009: failure of full resync command on default channel at 03/13/2019 19:52:30
RMAN-10015: error compiling PL/SQL program
RMAN-10014: PL/SQL error 0 on line 3244 column 3: Statement ignored
RMAN-10014: PL/SQL error 302 on line 3244 column 22: component 'GETPOLLEDREC' must be declared
RMAN-10014: PL/SQL error 0 on line 2280 column 6: Statement ignored
RMAN-10014: PL/SQL error 306 on line 2280 column 13: wrong number or types of arguments in call to 'BEGINRMANOUTPUTRESYNC'
RMAN-10014: PL/SQL error 0 on line 1757 column 12: Statement ignored
RMAN-10014: PL/SQL error 306 on line 1757 column 12: wrong number or types of arguments in call to 'CHECKTABLESPACE'
RMAN-10014: PL/SQL error 0 on line 1189 column 9: Statement ignored
RMAN-10014: PL/SQL error 302 on line 1189 column 25: component 'ISROUTDUPLICATERECORD' must be declared
Recovery Manager complete.
SOLUTION :
il faut AUSSI (condition mal documentée) mettre à jour le CATALOG RMAN.
Procédure :
Connexion à une base quelconque , en ouvrant le catalogue
$ . oraenv
ORCL
$ rman target / catalog RMAN/RMANPASSWD@RMAN
RMAN> upgrade catalog;
recovery catalog owner is RMAN
enter UPGRADE CATALOG command again to confirm catalog upgrade
RMAN> upgrade catalog;
recovery catalog upgraded to version 11.02.00.04
DBMS_RCVMAN package upgraded to version 11.02.00.04
DBMS_RCVCAT package upgraded to version 11.02.00.04Ressortir de RMAN et revenir afin qu'il reconnecte le catalog par rapport à la base, sinon on aura l'erreur :
RMAN-06004: ORACLE error from recovery catalog database: RMAN-20021:
database not set
RMAN-06031: could not translate database keyword)
Lancer ensuite une commande quelconque, list backup par exemple, ce qui force la resynchronisation :
RMAN> list backup summary;
starting full resync of recovery catalog
full resync complete
La resynchronisation remonte dans le catalogue RMAN les backups présents dans les control files, s'il y en a. Après le resync, tous les backups sont donc accessibles à partir du catalogue.
Erreurs en connexion SYSDBA sous windows
ORA-01031
En connexion SYSDBA avec SQLPLUS sous Windows, on a l'erreur :
ORA-01031: insufficient privileges
Solution :
Editer dbhome_1\NETWORK\ADMIN\SQLNET.ORA
Changer SQLNET.AUTHENTICATION_SERVICES=(NONE) en "(NTS)"
ORA-12560
en connexion locale SYSDBA avec sqlplus sous Windows, bien que l'utilisateur appartienne bien au groupe oradba, on a une erreur :
TNS-12560: TNS : erreur d'adaptateur de protocole
Verifier que le client Oracle n'a pas été installé par-dessus le serveur ! Dans ce cas, le PATH dirige par défaut vers sqlplus du client, qui n'a pas toutes les variables.
Il faut éditer le PATH pour supprimer les références au path "client_1"
RMAN duplicate erreur "ORA-01843"
RMAN termine avec cette erreur :
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: failure of Duplicate Db command at 10/10/2019 15:01:11
RMAN-05501: aborting duplication of target database
RMAN-03015: error occurred in stored script Memory Script
RMAN-06136: ORACLE error from auxiliary database: ORA-01843: ce n'est pas un mois valide
La commande DUPLICATE (peut arriver aussi avec RESTORE ou BACKUP) est pourtant formatée correctement
SET UNTIL TIME "to_date('09-10-2019_20:30:00','DD-MM-YYYY_HH24:MI:SS')";Mais parfois ça ne suffit pas. Il faut donc initialiser NLS_LANG avec le bon code page avant de lancer RMAN (en ligne de commande ou dans le script bash qui lance rman) :
export NLS_LANG=AMERICAN
Vérifier les possibilités de réduction des tablespaces
La requête suivante indique l'espace libre et surtout le HWM pour estimer les réductions de fichiers possibles :
set lines 2000
col file_name format A66
def blocksize = 4096
select file_name,
ceil( blocks*'&blocksize'/1024/1024) TOTAL,
ceil( (nvl(hwm,1)*'&blocksize')/1024/1024 ) HWM,
ceil( blocks*'&blocksize'/1024/1024) - ceil( (nvl(hwm,1)*'&blocksize')/1024/1024 ) RECOVERABLE
from dba_data_files a,
( select file_id, max(block_id+blocks-1) hwm
from dba_extents
group by file_id ) b
where a.file_id = b.file_id(+) and a.tablespace_name = '&tsname';Oracle 19 - impossible de créer le LISTENER
Au moment de créer le LISTENER (par dbca ou netca), Oracle renvoie l'erreur :
Parsing command line arguments:
Parameter "silent" = true
Parameter "local" = true
Parameter "inscomp" = server
Parameter "insprtcl" = TCP
Parameter "orahome" = /u01/app/oracle/product/19c/dbhome_1
Parameter "instype" = custom
Parameter "listener" = LISTENER
Parameter "lisport" = 1521
Parameter "cfg" = local
Parameter "responsefile" = /u01/app/oracle/product/19c/dbhome_1/network/install/netca_typ.rsp
Done parsing command line arguments.
Oracle Net Services Configuration:
LISTENER:The information provided for this listener is currently in use by other software on this computer.
Profile configuration complete.
Check the trace file for details: /u01/app/oracle/cfgtoollogs/netca/trace_OraDB19Home1-26012611AM3420.log
Oracle Net Services configuration failed. The exit code is 1Il faut vérifier :
1. /etc/hosts : l'adresse IP locale et le fqdn du serveur doivent avoir été ajoutés
2. la variable ORACLE_HOSTNAME, qui doit être initialisée également avec le fqdn
Oracle linux - l'utilisateur oracle ne voit pas le listener lancé par SYSTEMD
Sur un serveur Oracle, la ou les bases et listeners sont lancés par des services SYSTEMD (donc par root, qui lance les services sous le nom d'oracle).
Lorsqu'on se connecte avec l'utilisateur Oracle, il ne voit pas le LISTENER (lsnrctl status indique qu'il n'est pas lancé, alors que le service est bien démarré et qu'on voit le processus).
Le problème vient de la "polyinstanciation" de certains répertoires, c'est-à-dire la possibilité de rendre privés certains répertoires pour chaque utilisateur. Si les répertoire en question sont "/tmp" et/ou "/var/tmp", alors l'utilisateur oracle ne trouve pas les sockets créés par le service lancé par root, ses propres instances de répertoire ne contiennent rien. Il considère que le listener n'est pas lancé.
Pour désactiver la polyinstantiation :
Dans /etc/security/namespace.conf, commenter les lignes relatives à "/tmp" et "/var/tmp".
Analyse de toutes les tables et/ou des indexes
Pour analyser toutes les tables ou indexes d'un schéma, utiliser le script ci-dessous dans sqlplus. Pour les tables :
set pages 9999;
set heading off;
set feedback off;
set echo off;
set verify off;
column bname new_value dbname noprint
column hname new_value hstname noprint
select name as bname from v$database;
select host_name as hname from v$instance;
spool analyze_tables_&dbname._&hstname..sql;
prompt set echo on;
prompt set feedback on;
prompt spool analyze_tables_&dbname._&hstname..log;
select 'analyze table "'||owner||'"."'||table_name||'" validate structure;' from dba_tables
where
owner not in ('SYS','SYSTEM');
prompt spool off;
spool off;
@analyze_tables_&dbname._&hstname
set heading on;
set feedback on;
set echo on;
set verify on;Pour les indexes utiliser ce même script en remplaçant :
- ligne 12 : spool analyze_indexes_&dbname._&hstname..sql;
- ligne 17 : select 'analyze index "'||owner||'"."'||index_name||'" validate structure;' from dba_indexes;
- ligne 25 : @analyze_indexes_&dbname._&hstname
ASM - Automatic Storage Management - Tips&Tricks
Depuis la version 12.2 d'Oracle, l'utilisation d'ASM devient quasi-obligatoire. Mais est utilisable depuis la 11gR2.
Quelques commandes utiles
ASMCMD
La commande asmcmd permet de gérer ASM en ligne de commande. Il faut que les variables ORACLE_HOME et ORACLE_SID soient positionnées vers l'instance ASM, que l'utilisateur soit celui qui a lancé l'instance; et, jusqu'à la version 12.1, que cet utilisateur (oracle ou autre utilisateur dédié ASM) soit autorisé :
asmcmd --privilege sysdbahttps://docs.oracle.com/en/database/oracle/oracle-database/19/ostmg/about-asmcmd.html#GUID-65775DDE-611D-4C59-9696-BB91DB83B367
Notamment :
https://docs.oracle.com/en/database/oracle/oracle-database/19/ostmg/asmcmd-diskgroup-commands.html#GUID-3BA40908-0543-4968-B834-BD4D873E1059
https://hhutzler.de/blog/asm_commands
ASMCMD> lsdg
ASMCMD> lsdsk -k -gORACLEASM (gestion optionnelle d'ASM par ASMLib)
https://www.thegeekdiary.com/oracleasm-command-examples/
oracleasm est lancé sous l'utilisateur "root"
[root@prooem03 root]# oracleasm createdisk 'DISK1' '/dev/sdb1'
[root@prooem03 root]# oracleasm createdisk 'DISK2' '/dev/sdc1'
[root@prooem03 root]# oracleasm listdisksQuelques requêtes utiles
https://techgoeasy.com/asm-lesson-9-asm-queries/
(sur cette page voir notamment "Migrating to ASM Using RMAN")
Connexion à la base ASM avec SQLPLUS en SYSASM (avec l'utilisateur système créateur de l'instance ASM)
[oragrid ~] export ORACLE_BASE=/u01/app/grid_base
[oragrid ~] export ORACLE_HOME=/u01/app/grid/19c_home1
[oragrid ~] export ORACLE_SID=+ASM
[oragrid ~] sqlplus / as sysasmHOW TO CREATE A DISK GROUP
-- Si le disque n'a pas déjà été nommé (via oracleasm par exemple)
SQL> CREATE DISKGROUP DATA1 EXTERNAL REDUNDANCY disk '/dev/sdb1' NAME DISK1;
-- Si le disque a déjà un nom
SQL> CREATE DISKGROUP DATA1 EXTERNAL REDUNDANCY disk 'ORCL:DISK1' NAME DISK1;HOW TO ADD DISK IN A DISK GROUP
ALTER DISKGROUP DATA ADD DISK '/dev/sdc1';
ALTER DISKGROUP DATA ADD DISK'/dev/sdc*'REBALANCE POWER 5 WAIT;
ALTER DISKGROUP DATA ADD DISK'/dev/sdc5' NAME DISK5,'/dev/sdc6' NAME DISK6;HOW TO ADD REDO LOGS IN ASM (DATA1 & DATA2 ARE DISKGROUPS)
ALTER DATABASE ADD LOGFILE (+DATA1,+DATA2);HOW TO DROP DISK OR DISKGROUP
ALTER DISKGROUP DATA1 DROP DISK DISK2;
DROP DISKGROUP DATA1 INCLUDING CONTENTS;ASM DISK GROUPS and DISKS INFORMATION
-- SHOW AVAILABLE DISKS
set lines 999;
col diskgroup for a15
col diskname for a15
col path for a35
select a.name DiskGroup,b.name DiskName, b.total_mb, (b.total_mb-b.free_mb) Used_MB, b.free_mb,b.path,b.header_status
from v$asm_disk b, v$asm_diskgroup a
where a.group_number (+) =b.group_number
order by b.group_number,b.name;
-- DISKGROUPS
set pages 40000 lines 120
col NAME for a15
select GROUP_NUMBER DG#, name, ALLOCATION_UNIT_SIZE AU_SZ, STATE,TYPE, TOTAL_MB, FREE_MB, OFFLINE_DISKS from v$asm_diskgroup;
col PATH for a15
col DG_NAME for a15
col DG_STATE for a10
col FAILGROUP for a10
select dg.name dg_name, dg.state dg_state, dg.type, d.disk_number dsk_no,d.path, d.mount_status, d.FAILGROUP, d.state
from v$asm_diskgroup dg, v$asm_disk d
where dg.group_number=d.group_number order by dg_name, dsk_no;
-- DISKS
set pages 40000 lines 120
col PATH for a30
select DISK_NUMBER,MOUNT_STATUS,HEADER_STATUS,MODE_STATUS,STATE,PATH FROM V$ASM_DISK;
QUERY TO FIND THE FILES IN USE BY AN ASM INSTANCE
set lines 2000
col full_alias_path format a100
SELECT concat('+'||gname, sys_connect_by_path(aname, '/')) full_alias_path
FROM (SELECT g.name gname, a.parent_index pindex, a.name aname, a.reference_index rindex
FROM v$asm_alias a, v$asm_diskgroup g
WHERE a.group_number = g.group_number)
START WITH (mod(pindex, power(2, 24))) = 0
CONNECT BY PRIOR
rindex = pindex;REBALANCE INFORMATION
select GROUP_NUMBER, OPERATION, STATE, ACTUAL, SOFAR, EST_MINUTES from v$asm_operationQUERY TO DETECT FILES IN AN ASM DISKGROUP (replace "MDDX1" by required diskgroup name)
set lines 2000
col full_alias_path format a100
SELECT concat('+'||gname, sys_connect_by_path(aname, '/')) full_alias_path
FROM (SELECT g.name gname, a.parent_index pindex, a.name aname, a.reference_index rindex
FROM v$asm_alias a, v$asm_diskgroup g
WHERE a.group_number = g.group_number
AND g.name = 'MDDX1')
START WITH (mod(pindex, power(2, 24))) = 0
CONNECT BY PRIOR rindex = pindex;QUERY TO DETERMINE WHAT DISKGROUPS EXIST AND HOW FULL THEY ARE
SELECT NAME,TOTAL_MB,USABLE_FILE_MB FROM V$ASM_DISKGROUP;QUERY TO DETERMINE THE STATE AND BALANCE OF DISKGROUPS
Starting in 10.2 this can be easily done with one query
SELECT NAME,STATE,UNBALANCED FROM V$ASM_DISKGROUP;QUERY TO DETERMINE THE STATE OF THE DISKS WITHIN A DISKGROUP
col name format a12
col path format a25
col mount_status format a7
col header_status format a12
col mode_status format a7
col state format a8
SELECT D.NAME, D.PATH, D.MOUNT_STATUS, D.HEADER_STATUS, D.MODE_STATUS, D.STATE
FROM V$ASM_DISK D, V$ASM_DISKGROUP G
WHERE G.NAME = '&1'AND D.GROUP_NUMBER = G.GROUP_NUMBER;Ressources
https://oracle-base.com/articles/10g/automatic-storage-management-10g
Installation sur 19c
https://wadhahdaouehi.tn/2019/05/install-oracle-database-19c3-on-asm/
Tutoriaux
https://ittutorial.org/category/oracle/asm/
https://ittutorial.org/oracle-automatic-storage-management-18c-step-by-step-installation-1/
https://ittutorial.org/oracle-automatic-storage-management-18c-step-by-step-installation-2/
https://ittutorial.org/add-disk-and-drop-disk-operations-in-oracle-asm-oracle-automatic-storage-management-1-asm/
https://ittutorial.org/oracle-automatic-storage-management-asm-2-add-disk-and-drop-disk-operations-in-oracle-asm/
https://www.casesup.com/category/knowledgebase/howtos/how-to-prepare-disks-for-oracle-asm
Monitoring par script bash
https://www.learn-it-with-examples.com/database/oracle/maintenance-tasks/oracle-asm-disk-space-monitoring-bash-example.html
Déplacer/ajouterer/supprimer des disques
https://www.developpez.com/actu/177678/Oracle-ASM-decouvrez-une-methode-pour-apprendre-a-deplacer-vos-disques-sans-deni-de-service-DoS-un-billet-de-Fabien-Celaia
ASM - Déplacement d'une base complète à froid
Cas pratique : une base a été créée dans le mauvais disk group. On la déplace à froid de +DATA01 vers +DATA02.
Sous sqlplus, lister les fichiers existants
SELECT name FROM v$controlfile;
SELECT member FROM v$logfile;
SELECT name FROM v$datafile;
SELECT name FROM v$tempfile;
SHOW PARAMETER SPFILE;Dans une autre session (on aura besoin de asmcmd en parallèle tout au long de la procédure), créer l'arborescence à la destination
ASMCMD> mkdir +DATA02/MYBASE
ASMCMD> mkdir +DATA02/MYBASE/CONTROLFILE
ASMCMD> mkdir +DATA02/MYBASE/DATAFILE
ASMCMD> mkdir +DATA02/MYBASE/ONLINELOG
ASMCMD> mkdir +DATA02/MYBASE/PARAMETERFILE
ASMCMD> mkdir +DATA02/MYBASE/TEMPFILESous RMAN, déplacer les fichiers
rman target /
RMAN> startup nomount
RMAN> restore controlfile to '+DATA02' from '+DATA01/MYBASE/CONTROLFILE/current.266.1110624765';trouver le nouveau nom :
ASMCMD> ls DATA02/MYBASE/CONTROLFILE
+DATA02/MYBASE/CONTROLFILE/current.256.1111070599Changer dans le spfile
RMAN> SQL alter system set control_files='+DATA02/MYBASE/CONTROLFILE/current.256.1111070599' scope= spfile;Déplacer le spfile (la base le retrouvera automatiquement si on le déplace avec RMAN) et redémarrer la base en MOUNT
RMAN> restore spfile to '+DATA02';
RMAN> shutdown immediate
RMAN> startup mountCopier les fichiers un par un
RMAN> copy datafile '+DATA01/MYBASE/DATAFILE/system.259.1110624767' to '+DATA02';
Starting backup at 26-JUL-22
using target database control file instead of recovery catalog
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=1338 device type=DISK
channel ORA_DISK_1: starting datafile copy
input datafile file number=00001 name=+DATA01/MYBASE/DATAFILE/system.259.1110624767
output file name=+DATA02/MYBASE/DATAFILE/system.257.1111071189 tag=TAG20220726T145308 RECID=1 STAMP=1111071191
channel ORA_DISK_1: datafile copy complete, elapsed time: 00:00:03
Finished backup at 26-JUL-22
Starting Control File and SPFILE Autobackup at 26-JUL-22
piece handle=/u01/app/oracle/homes/OraDB19Home1/dbs/c-742892794-20220726-00 comment=NONE
Finished Control File and SPFILE Autobackup at 26-JUL-22Renommer le fichier dans le spfile (le nouveau nom est affiché dans la sortie du copy ci-dessus)
RMAN> SQL alter database rename file '+DATA01/MYBASE/DATAFILE/system.259.1110624767' to '+DATA02/MYBASE/DATAFILE/system.257.1111071189';Lorsque tous les fichiers ont copiés, repasser sous SQLPLUS pour la suite.
Déplacer le TEMPFILE
SQL> shutdown immediate
SQL> startup
SQL> alter system set db_create_file_dest='+DATA02';
SQL> alter tablespace TEMP add tempfile '+DATA02' SIZE 1G autoextend on next 100M maxsize unlimited;
SQL> select file_name from dba_temp_files;
FILE_NAME
--------------------------------------------------------------------------------
+DATA02/MYBASE/TEMPFILE/temp.265.1111074253
+DATA01/MYBASE/TEMPFILE/temp.263.1110624771
SQL> alter database tempfile '+DATA01/MYBASE/TEMPFILE/temp.263.1110624771' drop including datafiles;Déplacer les REDO LOGS
SQL> select GROUP#,THREAD#,STATUS from v$log;
GROUP# THREAD# STATUS
---------- ---------- ----------------
1 1 INACTIVE
2 1 INACTIVE
3 1 CURRENT
SQL> alter database drop logfile group 1;
SQL> alter database add logfile group 1 '+DATA02' size 300M;Si le groupe est "CURRENT" ou "ACTIVE", on ne peut pas le supprimer. Switch vers un autre groupe
SQL> alter system switch logfile;
SQL> alter system checkpoint;Terminer le nettoyage sous asmcmd (les sous-répertoires DATAFILE, TEMPFILE,... ont déjà été supprimés par RMAN)
ASMCMD> rm DATA01/MYBASE/CONTROLFILE/*
You may delete multiple files and/or directories.
Are you sure? (y/n) y
ASMCMD> rm DATA01/MYBASE/PARAMETERFILE/*
You may delete multiple files and/or directories.
Are you sure? (y/n) y
ASMCMD> rm DATA01/MYBASERelancer la base pour valider la nouvelle arborescence
SQL> shutdown immediate;
SQL> startupAWR (AUTOMATIC WORKLOAD REPOSITORY) - Tips&Tricks
Lister la configuration des snaphosts :
SQL> select
extract( day from snap_interval) *24*60+
extract( hour from snap_interval) *60+
extract( minute from snap_interval ) "Snapshot Interval",
extract( day from retention) *24*60+
extract( hour from retention) *60+
extract( minute from retention ) "Retention Interval"
from dba_hist_wr_control;Lister les snaphosts historisés :
SQL> set lines 220
SQL> set pages 999
SQL> SELECT snap_id, begin_interval_time, end_interval_time FROM dba_hist_snapshot ORDER BY 1;Générer le rapport (préférer awrrpti à awrrpt qui permet d'interroger une instance particulière) :
SQL> @$ORACLE_HOME/rdbms/admin/awrrpti.sql(répondre aux différentes questions)
Les recommandations ADDM à la fin du rapport sont sans doute la partie la plus intéressante, le reste est plutôt abscons...
Modifier l'écart par défaut (toutes les heures sur 7 jours glissants) entre les snapshots :
SQL> execute dbms_workload_repository.modify_snapshot_settings (retention=>40320, interval=>60);Vérifier la configuration :
SQL> select extract( day from snap_interval) *24*60+
extract( hour from snap_interval) *60+
extract( minute from snap_interval ) "Snapshot Interval",
extract( day from retention) *24*60+
extract( hour from retention) *60+
extract( minute from retention ) "Retention Interval"
from
dba_hist_wr_control;Créer manuellement un snapshot :
EXEC DBMS_WORKLOAD_REPOSITORY.create_snapshot;Supprimer des snapshosts :
BEGIN
DBMS_WORKLOAD_REPOSITORY.drop_snapshot_range (
low_snap_id => 22,
high_snap_id => 32);
END;
/Ressources
https://oracle-base.com/articles/10g/automatic-workload-repository-10g
AWR remplit le tablespace SYSAUX
https://thehelpfuldba.com/excessive-growth-in-sysaux-tablespace/
Vérifier si c'est bien AWR qui prend toute la place dans SYSAUX :
SQL> select OCCUPANT_NAME,SCHEMA_NAME,SPACE_USAGE_KBYTES/1024 from V$SYSAUX_OCCUPANTS order by 3 desc;
SQL> @?/rdbms/admin/awrinfo.sql
SQL> select * from (select bytes/1024/1024 size_mb, segment_name from dba_segments where tablespace_name='SYSAUX' order by 1 desc) where rownum<5;Faire le ménage dans les stats AWR (en fonction des tables les plus grosses affichées ci-dessus). Exemple :
truncate table WRH$_EVENT_HISTOGRAM;
truncate table WRH$_LATCH;
truncate table WRH$_SQLSTAT;
truncate table WRH$_SYSSTAT;
truncate table WRH$_ACTIVE_SESSION_HISTORY;NOTE : L'utilisation de
exec DBMS_STATS.PURGE_STATS(SYSDATE-7);n'a jamais vidé le tablespace SYSAUX, les truncate sont plus efficaces, et il est sans doute plus urgent de récupérer de la place dans SYSAUX que de conserver des statistiques d'utilisation.
Calculer la mémoire totale utilisée par une base
Principe : récupérer les IDs des processus triés par SID, et faire la somme.
SCRIPT sh :
sids=`ps -eaf | grep ora_pmon | grep -v " grep " | awk '{print substr($NF,10)}'`
username=`whoami`
total=0
for sid in $sids ; do
pids=`ps -eaf | grep "$username" | grep $sid | grep -v " grep " | awk '{print $2}'`
mem=`pmap $pids 2>&1 | grep "K " | sort | awk '{print $1 " " substr($2,1,length($2)-1)}' | uniq | awk ' BEGIN { sum=0 } { sum+=$2} END {print sum}' `
echo "$sid : $mem"
total=`expr $total + $mem`
done
echo "total : $total"Catalogue RMAN centralisé
Rappel :
RMAN = Recovery Manager d'Oracle.
RMAN stocke ses informations dans un référentiel (repository) qui se situe dans les Control Files de la base locale, ou dans un Catalogue (base de données) centralisé pour toutes les bases.
Créer une base Oracle dédiée à RMAN, appelons-la, simplement : RMAN,
par le moyen que vous préférez, manuellement, ou graphiquement.
Créer un Tablespace RMAN_CATALOG dans une nouvelle base dédiée RMAN
export ORACLE_SID=RMAN
sqlplus /nolog
SQL> CONNECT sys/mdp as SYSDBA
Connected.
SQL> CREATE TABLESPACE RMAN_CATALOG DATAFILE '/oradata/RMAN/rman_catalog_01.dbf' size 100M;
Tablespace created.Créer un utilisateur Oracle "rman"
SQL> CREATE USER rman IDENTIFIED BY rman DEFAULT TABLESPACE RMAN_CATALOG;
User created.
SQL> GRANT CONNECT, RESOURCE TO rman;
Grant succeeded.
SQL> GRANT RECOVERY_CATALOG_OWNER TO rman;
Grant succeeded.Créer le catalogue RMAN
export ORACLE_SID=RMAN
rman CATALOG rman/rman
Recovery Manager: Release 10.2.0.1.0 - Production on Mon Sep 20 03:18:13 2010
Copyright (c) 1982, 2005, Oracle. All rights reserved.
connected to recovery catalog database
RMAN> CREATE CATALOG;
recovery catalog created
RMAN> exit
Recovery Manager complete.Enregistrement d'une base de données DBTEST dans le catalogue
rman TARGET sys/mot_de_passe_sys@dbtest CATALOG rman/rman@base_rman
Recovery Manager: Release 10.2.0.1.0 - Production on Mon Sep 20 03:20:19 2010
Copyright (c) 1982, 2005, Oracle. All rights reserved.
connected to target database: DBTEST (DBID=875592259)
connected to recovery catalog database
RMAN> REGISTER DATABASE;
database registered in recovery catalog
starting full resync of recovery catalog
full resync completeIl ne reste plus qu'à lancer les sauvegardes, en se connectant à ce catalogue
rman target sys/mot_de_passe_sys@DBTEST catalog rman/rman@RMAN cmdfile backup_full.rman
Le script rman "backup_full.rman" contiendra par exemple :
BACKUP INCREMENTAL LEVEL 0 CUMULATIVE DEVICE TYPE DISK DATABASE;
BACKUP DEVICE TYPE DISK ARCHIVELOG ALL DELETE ALL INPUT;
BACKUP SPFILE;
ALLOCATE CHANNEL FOR MAINTENANCE TYPE DISK;
DELETE NOPROMPT OBSOLETE DEVICE TYPE DISK;
RELEASE CHANNEL;("BACKUP INCREMENTAL LEVEL 0" est à préférer au simple "BACKUP DATABASE" car il permettra par la suite d'enchaîner sur des incrémentales, ce qui n'est pas le cas du backup full simple).
Pour une sauvegarde incrémentale et/ou cumulative, on utilisera alors :
BACKUP INCREMENTAL LEVEL 1 DEVICE TYPE DISK DATABASE;
- ou -
BACKUP INCREMENTAL LEVEL 1 CUMULATIVE DEVICE TYPE DISK DATABASE;Pour la différence entre incrémentales et cumulatives, voir sur ce blog, par exemple.
Des exemples de scripts rman sont joints à cette page.
Déplacement d'une base complète vers un nouveau serveur avec changement du chemin des fichiers
La base ORCL va être déplacée d'un serveur ORACLESRC vers un nouveau serveur ORACLEDST, sans changement de version (Oracle 11g) ni changement de SID, mais changement des chemins des fichiers de la base de "/u01/orcl" vers "/oracle/data/orcl".
Si le SID doit changer, préférer plutôt une migration par RMAN, comme on le ferait pour une duplication de base.
Créer la nouvelle base sur le nouveau serveur. Une fois créée, la stopper tout de suite (on doit écraser ses fichiers !)
Si nécessaire (mais il a dû être recréé avec la nouvelle base) copier le fichier de mots de passe SYSDBA /u01/app/oracle/product/11.2.0/dbhome_1/dbs/orapwORCL de l'ancien serveur vers le nouveau.
Créer un script sql avec le code ci-dessous, à lancer sur la base source. Il génère lui-même un script sql "migration.sql" qui modifiera les chemins sur la base destination
-- Adapter le chemin ci-dessous selon la destination
define path='/oracle/data/orcl'
set pages 0
set lines 2000
set head off
set term off
set verify off
set feed off
spool migration.sql
select 'spool migration.log' from dual;
select 'startup nomount' from dual;
select 'alter system set control_files=''/&path/control01.ctl'', ''/redo1/&path/control02.ctl'', ''/redo2/&path/control03.ctl'' scope=SPFILE;' from dual;
select 'shutdown immediate' from dual;
select 'startup mount' from dual;
select 'alter database rename file '''||file_name||''' to ''/&path'||substr(file_name, instr(file_name,'/',-1))||''';' from dba_data_files;
select 'alter database rename file '''||file_name||''' to ''/&path'||substr(file_name, instr(file_name,'/',-1))||''';' from dba_temp_files;
select 'alter database rename file '''||member||''' to ''/redo1/&path/redo'||group#||'1.log'';' from v$logfile;
-- Si des ajouts de groupes REDO LOG sont nécessaires :
-- select 'ALTER DATABASE ADD LOGFILE MEMBER ''/redo2/&path/redo'||group#||'2.log'' to group '||group#||';' from v$logfile;
-- Modification des paramètres
select 'alter system set '||NAME||'='||VALUE||' scope=spfile;' from v$parameter where ISDEFAULT='FALSE' and NAME not in ('control_files','db_block_size','db_create_file_dest','db_recovery_file_dest','audit_file_dest','db_name','diagnostic_dest','db_domain','log_archive_format') and NAME not like '%file_name_convert' and NAME not like '\_%' and NAME not like 'nls_%' and NAME not like 'log_archive_dest%';
select 'alter system set '||NAME||'=LOCATION=/archive/&path scope=spfile;' from v$parameter where ISDEFAULT='FALSE' and NAME = 'log_archive_dest_1';
select 'spool off' from dual;
spool off
exitTransférer migration.sql vers le serveur destination.
Arrêter de la base source après déconnexion utilisateurs, applications tiers, etc.
Copier les fichiers de la base source vers le nouveau serveur (rsync ou scp, attention aux chemins !)
rsync -av --progress /u01/orcl/* ORACLEDST:/oracle/data/orcl/Exécuter le script migration.sql sur la base destination.
export ORACLE_SID=ORCL
sqlplus / as sysdba @migration.sqlRelancer de la base en mode normal, recompiler d'éventuels objets en erreur :
SQL> shutdown immediate;
SQL> startup;
SQL> @?/rdbms/admin/utlrp.sqlVérifier les archive log
SQL> archive log list
SQL> alter system switch logfile ;Vérifier les tnsnames des clients qui doivent accéder à cette nouvelle base.
Déplacer les fichiers d'une base
Pré-requis
Noter le nom de tous les fichiers avant déplacement :
SELECT name FROM v$controlfile;
SELECT member FROM v$logfile;
SELECT name FROM v$datafile;
SELECT name FROM v$tempfile;Déplacement à froid (base arrêtée)
Fichiers de contrôle
Les fichiers de contrôle sont déclarés dans le fichier d'init, ou le spfile. Si la base se lance avec le fichier texte, il suffit d'y modifier la ligne CONTROL_FILES. S'il s'agit du SPFILE :
ALTER SYSTEM SET control_files='/nouvel_emplacement/CONTROL01.CTL', '/nouvel_emplacement/CONTROL02.CTL', '/nouvel_emplacement/CONTROL03.CTL' SCOPE=SPFILE;Stopper la base de données juste après !
Déplacer les fichiers
- Arrêter la base de données
SHUTDOWN IMMEDIATE;- Copier ou déplacer (selon la place disponible - la copie est préférable pour ne pas perdre un fichier en cas de problème, réseau par exemple s'ils sont copiés sur un autre serveur) tous les fichiers vers la nouvelle destination.
Renommer les fichiers
Relancer la base sans ouvrir les fichiers de données :
STARTUP MOUNTpuis renommer les fichiers (le "FILENAME" correspond au chemin complet + le nom du fichier : changer de disque ou de répertoire revient donc à le renommer)
ALTER DATABASE RENAME FILE '/nouvel_emplacement/SYSTEM01.DBF' TO '/nouvel_emplacement/SYSTEM01.DBF';faire de même pour tous les autres fichiers de données, les fichiers temporaires (TEMP) et tous les REDO LOGS.
Ouvrir la base
ALTER DATABASE OPEN;Déplacement à froid (TABLESPACE/DATAFILE OFFLINE) - <= 11g
Un ou plusieurs fichiers d'un tablespace
ALTER TABLESPACE users OFFLINE NORMAL;Renommer tous les fichiers du tablespace sur disque. Puis :
ALTER TABLESPACE users
RENAME DATAFILE '/u02/oracle/rbdb1/user1.dbf',
'/u02/oracle/rbdb1/user2.dbf'
TO '/u02/oracle/rbdb1/users01.dbf',
'/u02/oracle/rbdb1/users02.dbf';
Puis repasser le tablespace ONLINE
ALTER TABLESPACE users ONLINE;Déplacement à chaud (base online) >=12c
Depuis la version 12c, on peut déplacer les fichiers à chaud directement dans Oracle.
ALTER DATABASE MOVE DATAFILE '/u02/oradata/ORCL/user01.dbf' TO '/u03/ORADATA/ORCL/user01.dbf';On peut ajouter l'option "KEEP" (garder le fichier source), et REUSE (si le fichier existe déjà à la destination).
Cette commande fonctionne aussi pour ASM :
-- Du système de fichiers vers ASM
ALTER DATABASE MOVE DATAFILE '/u01/oradata/ORCL/user01.dbf' TO '+DATA/data/ORCL/user01.dbf';
-- D'ASM vers ASM
ALTER DATABASE MOVE DATAFILE '+DATA/data/ORCL/user01.dbf' TO '+DATA2/data/ORCL/user01.dbf';
-- Si on veut utiliser OMF (exemple : de +DATA avec fichiers nommés vers +DATA2 en OMF)
ALTER SYSTEM SET DB_CREATE_FILE_DEST='+DATA2' SCOPE=BOTH;
ALTER DATABASE MOVE DATAFILE '+DATA/data/ORCL/user01.dbf';Fichiers redo logs
La procédure est la même que pour agrandir la taille des fichiers redo logs : il faut les supprimer et les recréer l'un après l'autre.
Redimensionner les fichiers REDO LOGs
Déplacement/redimensionnement d'un tablespace temporaire à chaud
Noter les options (notamment d'autoextend, next et maxsize) dasn la table DBA_TEMP_FILES. Puis :
CREATE TEMPORARY TABLESPACE temp2 TEMPFILE '/nouvel_emplacement/TEMP2.DBF' SIZE 5M REUSE;
ALTER DATABASE DEFAULT TEMPORARY TABLESPACE temp2;
DROP TABLESPACE temp INCLUDING CONTENTS AND DATAFILES;
CREATE TEMPORARY TABLESPACE temp TEMPFILE '/nouvel_emplacement/TEMP01.DBF' SIZE 500M REUSE AUTOEXTEND ON NEXT 1M MAXSIZE unlimited;
ALTER DATABASE DEFAULT TEMPORARY TABLESPACE temp;
DROP TABLESPACE temp2 INCLUDING CONTENTS AND DATAFILES;Déplacer un LOB dans un autre tablespace
Stopper le listener pour éviter les connexions utilisateurs, et relancer la base pour couper les sessions en cours.
Puis créer si nécessaire un tablespace dédié aux LOB, et y déplacer le LOB d'une table :
CREATE TABLESPACE "DATLOB" DATAFILE '/mydb/DATLOB_1.DBF' SIZE 104857600 AUTOEXTEND ON NEXT 104857600 MAXSIZE 32767M, '/mydb/DATLOB_2.DBF' SIZE 209715200 AUTOEXTEND ON NEXT 104857600 MAXSIZE 32767M LOGGING ONLINE PERMANENT BLOCKSIZE 8192 EXTENT MANAGEMENT LOCAL AUTOALLOCATE DEFAULT NOCOMPRESS SEGMENT SPACE MANAGEMENT AUTO;
alter table MYSCHEMA.TABLEWITHLOB enable row movement;
alter table MYSCHEMA.TABLEWITHLOB move lob (lobcolumn) store as ( tablespace DATLOB);
alter table MYSCHEMA.TABLEWITHLOB disable row movement;arrêter et relancer de la base de données.
Déplacer une base vers un nouveau serveur en changeant les chemins des fichiers
Pour déplacer une base d'un serveur vers un autre, sans changement de version, le plus simple est de créer une base vide avec le même SID à la destination, d'arrêter la base source, et copier les fichiers à la destination. Mais si les chemins des fichiers diffèrent, il faut les modifier avant d'ouvrir la nouvelle base.
Ici on crée directement avec sqlplus un script SQL qu'il suffira de lancer à la destination une fois les fichiers copiés.
define path='nouveau_chemin'
set pages 0
set lines 2000
set head off
set term off
set verify off
set feed off
select 'spool MYBASE_migration.log' from dual;
select 'startup nomount' from dual;
select 'alter system set control_files=''/&path/control01.ctl'', ''/redo1/&path/control02.ctl'', ''/redo2/&path/control03.ctl'' scope=SPFILE;' from dual;
select 'shutdown immediate' from dual;
select 'startup mount' from dual;
select 'alter database rename file '''||file_name||''' to ''/&path'||substr(file_name, instr(file_name,'/',-1))||''';' from dba_data_files;
select 'alter database rename file '''||file_name||''' to ''/&path'||substr(file_name, instr(file_name,'/',-1))||''';' from dba_temp_files;
-- CHECK REDOS PATHS !
select 'alter database rename file '''||member||''' to ''/&path'||group#||'1.log'';' from v$logfile;
-- select 'ALTER DATABASE ADD LOGFILE MEMBER ''/other_path_redo/&path/redo'||group#||'2.log'' to group '||group#||';' from v$logfile; -- IF NECESSARY
select 'alter system set '||NAME||'='||VALUE||' scope=spfile;' from v$parameter where ISDEFAULT='FALSE' and NAME not in ('control_files','db_block_size','db_create_file_dest','db_recovery_file_dest','audit_file_dest','db_name','diagnostic_dest','db_domain','log_archive_format') and NAME not like '%file_name_convert' and NAME not like '\_%' and NAME not like 'nls_%' and NAME not like 'log_archive_dest%';
-- CHECK ARCHIVES PATH !
select 'alter system set '||NAME||'=LOCATION=/archives/&path scope=spfile;' from v$parameter where ISDEFAULT='FALSE' and NAME = 'log_archive_dest_1';
select 'spool off' from dual;
Duplication par RMAN avec changement de SID, et de chemin des fichiers.
Un script bash DUPLIQUER_ORASRC_ORADST.sh automatisant la procédure ci-dessous est joint à cette page
Etape 1: Passer notre base en mode "ARCHIVELOG"
lancer l'utilitaire SQL+ en tapant sqlplus / nolog
SQL> Connect / as sysdba (attention, il faut etre en local pour executer cette commande)
SQL> SHUTDOWN IMMEDIATE;
SQL> STARTUP MOUNT;
SQL> ALTER DATABASE ARCHIVELOG;
SQL> ALTER DATABASE OPEN;Etape 2: Effectuer une sauvegarde complète de la base.
Dans le cas, ou nous avons plusieurs bases sur notre machine, nous positionnons la variable d'environnement sur la base à dupliquer.
EXPORT ORACLE_SID=ORADBNous pouvons maintenant appeler l'utilitaire RMAN
RMAN> CONNECT TARGET /
RMAN> BAKCUP FULL DATABASE PLUS ARCHIVELOG DELETE ALL INPUT;Etape 3: Créer l'arborescence pour accueillir la base clonée.
ex: /ORACLE/PRODUCT/10.2.0/admin/ORADB pour les répertoires pfile,udump,bdump,...
et /ORACLE/PRODUCT/10.2.0/ORADATA/ORADB pour les fichiers de données, redo, ....
Si nous voulons que la nouvelle base s'appelle DUP, il faut alors créer une arborescence du type
/ORACLE/PRODUCT/10.2.0/admin/DUP et créer les différents répertoires comme pour ORADB
et également créer /ORACLE/PRODUCT/10.2.0/ORADATA/DUP à vide.
Etape 4: Créer un fichier init.ora pour la base DUP.
Pour cela, nous allons tout simplement copier le init.ora (qui peut avoir un autre nom) qui se trouve dans /ORACLE/PRODUCT/10.2.0/admin/ORADB/pfile dans /ORACLE/PRODUCT/10.2.0/admin/DUP/pfile.
Par sécurité, le regénérer avec les derniers paramètres en cours par :
SQL> CREATE PFILE='/ORACLE/PRODUCT/10.2.0/admin/pfile/initORADB.ora' FROM SPFILE;Pour simplifier, si ce n'est pas le cas, renommez-le initDUP.ora
Il va maintenant falloir éditer ce fichier init.ora pour remplacer ORADB par DUP partout dans le fichier (emplacement de fichier, nom de base), utiliser la fonction "rechercher & remplacer" de votre éditeur pour être sur de ne pas en oublier.
Cela n'est cependant pas suffisant, nous allons ajouter à la fin de notre fichier init.ora fraîchement modifié les deux lignes suivantes:
db_file_name_convert=('/ORACLE/PRODUCT/10.2.0/ORADATA/ORADB','/ORACLE/PRODUCT/10.2.0/ORADATA/DUP')
log_file_name_convert=('/ORACLE/PRODUCT/10.2.0/ORADATA/ORADB','/ORACLE/PRODUCT/10.2.0/ORADATA/DUP')
instance_name='DUP'
Note : ATTENTION à la casse, surtout sous unix ! En cas d'erreur, si on modifie des paramètres dans l'init.ora, penser à arrêter/redémarrer la base DUP pour les prendre en compte !
A TESTER : Si DUP existe déjà, on initialise simplement DB_FILE_NAME_CONVERT via alter system, directement dans le SPFILE ?
ATTENTION : Modifier également le cas échéant les paramètres relatifs à la mémoire (SGA & PGA) afin de ne pas utiliser la totalité de la RAM disponible sur votre serveur.
Etape 5 : Créer une nouvelle instance, si elle ne l'est pas déjà.
Par la méthode (manuelle, graphique) qui convient.
Etape 6: Démarrer l'instance créée.
Vérifier dans le TNSNAMES.ORA que les 2 bases sont bien déclarées, nous en aurons besoin pour RMAN.
Nous allons démarrer l'instance DUP en mode nomount et indiquer le fichier ora à utiliser pour lancer l'intance.
EXPORT ORACLE_SID=DUP
sqlplus / nologSQL> CONNECT / AS SYSDBA
SQL> STARTUP NOMOUNT pfile='/ORACLE/PRODUCT/10.2.0/admin/pfile/initDUP.ora';
SQL> QUITEtape 7: Clonage de la base ORADB
SUPPRIMER les fichiers de données existants dans le répertoire ORADATA de la bsae DUP, ils pourraient entrer en conflit avec les fichiers que RMAN va dupliquer.
EXPORT ORACLE_SID=DUP
rman target sys/oracle@ORADB auxiliary /RMAN> DUPLICATE TARGET DATABASE TO DUP
pfile=/ORACLE/PRODUCT/10.2.0/admin/pfile/initDUP.ora
logfile
'/ORACLE/PRODUCT/10.2.0/ORADATA/redo01.dbf' size 50m,
'/ORACLE/PRODUCT/10.2.0/ORADATA/redo02.dbf' size 50m,
'/ORACLE/PRODUCT/10.2.0/ORADATA/redo01.dbf' size 50m;Un message :
RMAN-05001: auxiliary filename '%s' conflicts with a file used by the target database
indique une erreur dans les paramètres *_file_name_convert. Vérifier les chemins et la casse.
Il suffit d'attendre un peu, et finalement la duplication se termine, connectez vous alors à DUP et vérifiez que vos users, schémas sont bien présents.
Recréer le spfile :
SQL>CREATE SPFILE FROM PFILE='/ORACLE/PRODUCT/10.2.0/admin/pfile/initDUP.ora';Tester ce SPFILE en arrêtant/redémarrant la base :
SQL> SHUTDOWN IMMEDIATE
SQL> STARTUPNous n'avons plus besoin des paramètres *_file_name_convert.
SQL>ALTER SYSTEM RESET db_file_name_convert SCOPE=SPFILE SID='*';
SQL>ALTER SYSTEM RESET log_file_name_convert SCOPE=SPFILE SID='*';Si vous avez passé votre base en ARCHIVELOG pour effectuer ces opérations, vous pouvez la repasser en mode NOARCHIVELOG. Pour cela rien de plus simple.
expdp COHERENT (flashback_scn ou flashback_time)
l'option COHERENT n'existe plus sur Datapump. On le simule avec les option FLASHBACK_*.
FLASHBACK_TIME
Ajouter aux options de expdp :
FLASHBACK_TIME="TO_TIMESTAMP(TO_CHAR(SYSDATE,'YYYY-MM-DD HH24:MI:SS'),'YYYY-MM-DD HH24:MI:SS')"ou
FLASHBACK_TIME=SYSTIMESTAMPFLASHBACK_SCN
SQL> select current_scn from v$database;
CURRENT_SCN
-----------
728886 Ajouter aux options de expdp :
FLASHBACK_SCN=728886Forcer sqlplus en sysdba sur une base morte
Si on arrive pas à se connecter même en local par sqlplus parce que la base est VRAIMENT malade, on peut essayer de forcer la connexion :
sqlplus -prelim / as sysdbaFull upgrade 11g -> 19c après transfert des fichiers
https://ocptechnology.com/how-to-upgrade-11g-to-19c-manually/
https://www.oracle.com/africa/a/tech/docs/twp-upgrade-oracle-database-19c.pdf
La migration va se faire d'un serveur SRVORA11G avec Oracle 11g vers un nouveau serveur SRVORA19C avec Oracle 19c.
Le chemin des fichiers Oracle reste le même entre les deux serveurs, il n'y a donc pas de renommage à faire. Dans le cas contraire, se reporter à la procédure avec changement des chemins des fichiers.
Toutes les commandes ci-dessous seront réalisées sous l'utilisateur linux "oracle" avec lequel sont installé les binaires 11g et 19c.
Sur les 2 serveurs :
mkdir /oracle/preupgrade/Sur SRVORA19C, créer une base vide afin de préparer l'arborescence des fichiers et de l'environnement. Stopper la base après création.
Sur SRVORA11G
transfert du script preugrade de la 19c sur le serveur 11g, et lancement
scp SRVORA19C:/oracle/ora19c/dbhome/rdbms/admin/preupgrade.jar /oracle/preupgrade/
export ORACLE_SID=ORCL
/oracle/ora11g/dbhome/jdk/bin/java -jar /oracle/preupgrade/preupgrade.jar FILE DIR /oracle/preupgrade/Préparation de la base 11g
sqlplus / as sysdba
SQL> SELECT version FROM v$timezone_file;
SQL> purge dba_recyclebin;
SQL> EXEC DBMS_STATS.GATHER_DICTIONARY_STATS;
SQL> create pfile from spfile;
SQL> shutdown immediate;Copie des 2 fichiers SQL générés par le script preupgrade, et de l'init.ora, vers SRVORA19C
scp /oracle/preupgrade/*upgrade_fixups.sql SRVORA19C:/oracle/preupgrade/
scp /oracle/ora11g/dbhome/dbs/initORCL.ora SRVORA19C:/oracle/ora19c/dbhome/dbsPuis copie des fichiers de la base 11g vers SRVORA19C
rsync -av --progress /u01/orcl/* SRVORA19C:/u01/orcl/
rsync -av --progress /u01/redo1/* SRVORA19C:/u01/redo1/
rsync -av --progress /u01/redo2/* SRVORA19C:/u01/redo2/Sur SRVORA19C
modifier initORCL.ora (enlever les paramètres dynamiques, modifier *.compatible='19.0.0'), créer le SPFILE
SQL> create spfile from pfile;NOTE : si nécessaire, ajouter un peu de RAM (paramètres memory_max_target et memory_target) à la base car la 19 est plus gourmande.
Démarrer la base en mode UPGRADE et lancer le premier script généré par preupgrade
SQL> startup upgrade
[...]
SQL>@/oracle/preupgrade/preupgrade_fixups.sql
ERROR:
ORA-04023: L'objet SYS.STANDARD n'a pas pu etre valide ou autoriseNOTE : cette erreur peut être ignorée depuis la 12c si on utilise le script en ligne de commande, plutôt que l'upgrade par le script catupd.sql.
Lancer l'upgrade
cd $ORACLE_HOME/bin
./dbupgrade
[...]
cd $ORACLE_HOME/rdbms/admin
sqlplus / as sysdba
SQL> startup
SQL> @catuppst.sql
SQL> @utlrp.sqlValider les statistiques et lancer le second script postupgrade
SQL> EXECUTE DBMS_STATS.GATHER_FIXED_OBJECTS_STATS;
SQL>@/oracle/preupgrade/postupgrade_fixups.sqlRelancer la base en mode normal
SQL> shutdown immediate;
SQL> startupGestion des JOBs
1. user doit avoir le droit EXECUTE sur SYS.DBMS_JOB
2. job_queue_processes doit être > 0 (modification possible en ligne avec alter system depuis 8.1.7)
connect user/password@DATAPROD
create table user.test_job (
date_lancement date);
/
create or replace procedure user.my_test_job is
begin
insert into user.test_job values (sysdate);
commit;
end my_test_job;
/
-- Verification du lancement : la date/heure doivent être dans test_job
select to_char(date_lancement,'HH24:MI:SS') date_lancement from user.test_job;
/
-- Soumission d'un job unique (pour répéter, ajouter sysdate+1 (tous les jours) ou sysdate+1/1440 (toutes les minutes)
-- à la fin de dbms_job.submit, entre la date initiale et la dernière parenthèse
DECLARE
jobno number;
begin
dbms_job.submit(jobno, --numero automatique par Oracle
'begin
my_test_job;
end;',
to_date('12-12-2006 10:59:00','dd-mm-yyyy hh24:mi:ss'));
commit ;
end ;
/
-- Suppression d'un job (uniquement par le user propriétaire, voir les numéros de jobs dans user_jobs (cf + bas))
exec dbms_job.remove(49);
/
-- forcer le lancement d'un job planifié
exec dbms_job.run('50');
/
-- voir les numeros de jobs de tous les users
connect system/manager@DATAPROD
select substr(to_char(job),1,2) jo,substr(schema_user,1,10) jouser,substr(what,1,20) jowhat,
to_char(last_date,'DD/MM/YY HH24:MI') jolast,to_char(next_date,'DD/MM/YY HH24:MI') jonext,failures from dba_jobs
/HA niveau 1 : Failover database sur Standard Edition
Introduction
The goal of this procedure is to install and configure an Oracle failover database. Like Standby or DataGuard databases, the failover db is on another server, but unlike them, Oracle is down on this server, so it requires no license. The instance is started ONLY if the production server crashes, and the production db is down or dead.
To recover the most recent datas from the primary server, a manual “standby -like” process is configured. First we transfer manually the archive logs and a snapshot copy of the control files every 15 minutes from primary to failover server. Then, at night, we transfer the daily Rman backup from primary to failover server.
In case of crash, the failover control files will be replaced by the copy from the primary database, and datafiles will be restored from the backup. Eventually some archive logs are restored from the backup file if rman find that it lakes in the archive directory. As the control files are most recent than restored files, the archived logs are used to recover datas to the last SCN.
The loss of records is maximum of 15 minutes, which is the delay, adjustable in the scheduled task, between two copy of the control files from the production server.
Items to install
In this procedure, the servers will be called TEST1 for the production server, and TEST2 for the failover server.
Oracle 10g
Install Oracle 10g binaries on the two servers, and create a database on each with the same directory tree for datafiles, and the same SID.
It's important because the control files used when activating the failover database will be those from production server, with the SID and all the paths on this server.
We consider that you know how installing Oracle, and here are only the specific configurations.
The databases will have “ORA” for SID in the rest of the procedure. Replace ORA with your SID in the commands and services name.
Put the production database in ARCHIVELOG mode.
On the failover server, go to the “Manage” mmc by right-clicking on “My computer”, then Services and Applications, then Services, and edit the properties of OracleServiceORA. Choose “manual” as startup type, and stop it.
Do the same with the DBConsoleORA service.
CwRsync
Rsync is a tool, coming from unix systems, which synchronize two or more directories on a same computer or between two or more computers.
CwRsync (for “CygWing Rsync”) is a Windows port of this tool. It can synchronize files through two ways :
- using SSH tunneling, it's the default on most unix machines, where ssh server and client are installed with the system (on Windows servers you must install and configure OpenSSH)
- using the rsync client-server specific protocol
We'll use here the second solution which is easier to implement.
Get the last version of server and client here :
http://sourceforge.net/project/showfiles.php?group_id=69227&package_id=68081
The latest version is 2.1.5 in the writing of this procedure.
Install by uncompress, then by launching the executable, the server on the production server, and the client on the failover server. Let all parameters by default.
Configuration
We consider in this part that you know how scheduling a task in Windows.
Oracle10g on the production server
Daily backup
First, we create some RMAN scripts to back up the database, the archivelog files, and to generate a snapshot copy of the control files. Put all the files in a proper directory, for example “C:\ORABACKUP\RMAN”.
A directory “C:\ORABACKUP\ORA” must be created too to receive the backups (see the Rman “CONFIGURE CHANNEL” parameter bellow).
Backup command script RMAN_BCK_FULL.BAT:
@echo off
set ORACLE_SID=ORA
rman log=rman_config.log target / cmdfile rman_config.rman
rman log=rman_full.log target / cmdfile rman_bck_full.rman
rman log=rman_valid_restore.rman.log target / cmdfile rman_valid_restore.rman
rman log=rman_maintenance.rman.log target / cmdfile rman_maintenance.rman
rman log=rman_orafiles_copy.rman.log target / cmdfile rman_orafiles_copy.rmanThis command file is scheduled at 04:00 AM each day. It launches some Rman scripts. The first, RMAN_CONFIG.RMAN, force the configuration of Rman parameters :
# rman_conf
#This script configure RMAN. It must be run only once.
CONFIGURE DEFAULT DEVICE TYPE TO DISK;
CONFIGURE RETENTION POLICY TO REDUNDANCY 2;
CONFIGURE DEVICE TYPE DISK PARALLELISM 1;
CONFIGURE CHANNEL DEVICE TYPE DISK FORMAT 'C:\orabackup\ORA\%U';
#Autobackup control file to flash_recovery_area
CONFIGURE CONTROLFILE AUTOBACKUP ON;Then we start the backup with RMAN_BCK_FULL.RMAN :
# rman_bck_full
# This script do a FULL backup
# Run it once a week
# The database must be in ARCHIVELOG mode to do a hot backup
BACKUP AS COMPRESSED BACKUPSET DATABASE PLUS ARCHIVELOG DELETE ALL INPUT ;
BACKUP SPFILE;
ALLOCATE CHANNEL FOR MAINTENANCE TYPE DISK;
DELETE NOPROMPT OBSOLETE DEVICE TYPE DISK;
RELEASE CHANNEL;We validate the backup with RMAN_VALID_RESTORE.RMAN :
# rman_valid_restore
#Run this script when you want to control that RMAN can restore database with existing backups
RESTORE DATABASE VALIDATE;We do some maintenance tasks with RMAN_MAINTENANCE.RMAN :
# rman_maintenance
# It check for obsolete backups (see REDUDANCY parameter) and delete them
CROSSCHECK BACKUP OF DATABASE;
CROSSCHECK ARCHIVELOG ALL;
REPORT NEED BACKUP;
DELETE NOPROMPT OBSOLETE;
# To delete a specific backup do this :
#LIST BACKUP;
#DELETE BACKUPPIECE numero_BP;
# Print all existing backups
LIST BACKUP SUMMARYAnd finally we back up the SPFILE and the PASSWORD file of the database with RMAN_ORAFILES_COPY.RMAN :
# rman__orafiles_copy
#Run this script when you want to backup (host copy) SPFILE and PWD file
HOST 'COPY C:\oracle\product\10.2.0\db_1\dbs\SPFILEORA.ORA C:\orabackup\ORA\';
HOST 'COPY C:\oracle\product\10.2.0\db_1\database\PWDORA.ORA C:\orabackup\ORA\';Archive log forced and control files snapshot
At regular intervals, we force a redo log switch to generate an archive log file, and we back up the control files for sending a copy to the failover server. The following script, RMAN_BCK_CONTROLFILE.BAT, is scheduled every 15 minutes :
@echo off
set ORACLE_SID=ORA
del /Q /F c:\oradata\ORA\archives\control.back
sqlplus /nolog @switchlog.sql
rman log=rman_bck_controlfile.log target / cmdfile rman_bck_controlfile.rmanIt lauches a sql script SWITCHLOG.SQL :
connect / as sysdba
alter system switch logfile;
exitIt launches also RMAN_BCK_CONTROLFILE.RMAN script :
# rman_bck_controlfile
# This script do a backup of controlfile
BACKUP AS COPY CURRENT CONTROLFILE FORMAT 'C:\oradata\ORA\Archives\control.back';The copy of the control file is recorded in the “Archives” directory of the database, the same where the archive logs files are created, because all this files will be synchronized with the failover server.
Oracle 10g on the failover server
On this server, we copy all the command and Rman scripts from the production server. The daily backup script will be used if this server become the production server.
You can schedule a task for the backup. Just deactivates it (on the scheduled task properties, uncheck the “Enabled” box at the bottom of the first tab), you will enable it if necessary.
Moreover, we create a script to restore and recover the database if the production server is down. Here is the RMAN_RESTORE_RECOVERY.CMD command file :
@echo off
REM Restore control files
copy C:\oradata\ORA\Archives\control.back C:\oradata\ORA\control01.ctl
copy C:\oradata\ORA\Archives\control.back C:\oradata\ORA\control02.ctl
copy C:\oradata\ORA\Archives\control.back C:\oradata\ORA\control03.ctl
REM delete old redo logs
del /Q /F C:\oradata\ORA\REDO*.LOG
REM Start Windows service
net start OracleServiceORA
REM Restore and recover database
rman log=rman_restore_recovery.log @rman_restore_recovery.rmanIt replaces the control files with the last snapshot received from the production server, then delete the redo logs (there will be re-created by the RESETLOGS option of the OPEN statement, later). Then we start the Oracle service.
At this point, the service try to start the database, but the datafiles are not up to date, and the start fails.
Now we mount, restore, recover and open (with RESETLOGS) the database with the Rman script RMAN_RESTORE_RECOVERY.RMAN :
# rman_restore_recovery
#Do a full database reco very
#we need all configuration files :
#spfile, tnsnames.ora, and listener.ora at right location
#Put the DBID on the following line :
SET DBID 3309712888;
CONNECT TARGET /;
STARTUP NOMOUNT;
RUN
{
ALTER DATABASE MOUNT;
# SET UNTIL TIME 'SYSDATE-3';
RESTORE DATABASE CHECK READONLY;
RECOVER DATABASE;
ALTER DATABASE OPEN RESETLOGS;
}
#if an ORA-01152 error occurs, do that :
#SQL> recover database until cancel using backup controlfile;
#SQL> Alter database open resetlogs;Note that we must put the DBID of the production database (which will be restored here) in this file. It's necessary because Oracle is not started up at the launch of Rman, so it can't find this DBID in memory.
To find it, do the following on the production server, on a command line :
C:\> set ORACLE_SID=ORA
C:\> RMAN TARGET /
Recovery Manager: Release 9.2.0.4.0 - 64bit Production
Copyright (c) 1995, 2002, Oracle Corporation. All rights reserved.
connected to target database: ORA (DBID=3309712888)
using target database controlfile instead of recovery catalog
RMAN> exit
C:\>Copy the DBID and report it in the RMAN_RESTORE_RECOVERY.RMAN file.
CwRsync
Server side on the production server
Here, the installation of the server cwRsync must have created a “Rsync_server” Windows service. Check it. Note that a new user has been created for this service (see in the “Log On” tab), be sure to give a READ privilege on the two directories used by Rsync (backup and archive directory, see bellow).
Then go to %PROGRAMFILES%\cwrsync_server directory, and edit the rsyncd.conf file. In this file, we configure the shares which will be managed by the rsync service.
Modify the “[test]” sample block, it becomes a “[orabackup]” share pointing to the directory where are stored the daily backups, then create a “[Oraarchives]” share on the directory where are stored the archive log files and the snapshot copy of the control files :
use chroot = false
strict modes = false
hosts allow = *
log file = rsyncd.log
pid file = rsyncd.pid
# Module definitions
# Remember cygwin naming conventions : c:\work becomes /cygwin/c/work
#
[Orabackup]
path = /cygdrive/c/orabackup/ORA
read only = true
transfer logging = yes
[Oraarchives]
path = /cygdrive/c/oradata/ORA/Archives
read only = true
transfer logging = yesNote the CygWin notation of the directory path, beginning with “cygdrive”, then the drive letter, then the full path, and the use of “/” instead of “\”.
Restart the rsyncd service in the management console to load the new configuration.
Client side on the failover server
On this server, we create two command scripts. Use a copy of the sample file provided with Rsync client, “cwrsync.cmd” in the directory %PROGRAMFILES%\cwRsync, because all the required variables are initialized at the beginning of the script.
We'll give here only the useful line added at the bottom of the file, note all the variables and comments that we leave unchanged.
The first script, CWRSYNC_ORABACKUP.CMD, synchronizes the backup every night from the production server, it is scheduled at 04:00 AM :
rsync -r TEST1::Orabackup /cygdrive/c/orabackup/ORA --delete- The “-r” option means that the remote subdirectories of the share will be synchronized too
- then we give the rsync server host name and the share name
- then the local directory (in cygwin notation) to which the files will be synchronized
- finally, the “--delete” option tells rsync to delete local files if there are deleted on the remote host.
The second script, CWRSYNC_ORAARCHIVES.CMD, synchronizes the archive log files and the control files snapshot, it is scheduled every 15 minutes :
rsync -r TEST1::Oraarchives /cygdrive/c/oradata/ORA/Archives --deleteSteps to switch to the failover database
On normal operations, the production database on TEST1 is up, and the failover database on TEST2 is down.
If a crash occurs on TEST1 :
- Be sure to completely stop TEST1 host to avoid conflicts (Host IP, Oracle SID...)
- Launch RMAN_RESTORE_RECOVERY.CMD on TEST2 to recover and start the database
- Change the IP address of the server, give it the IP of TEST1, so the clients will find it without changing their TNSNAME.ORA file
OR
- Modify DNS, change the IP of “TEST1” entry to point to “TEST2”
OR
- Use a DNS alias, just change the hostname behind the alias to point to “TEST2”
- Disable the scheduled tasks on CWRSYNC_ORABACKUP.CMD and CWRSYNC_ORAARCHIVES.CMD in the tasks properties
- Enable the backup (RMAN_BCK_FULL.BAT) scheduled task
- Change the startup type of OracleServiceORA from “manual” to “automatic” in the service management console.
Steps to switch back to the production server
- Re-install and configure the server, Oracle, Rsync server, and the command and Rman scripts on TEST1.
- Stop the database on TEST2, actually in production. Back up it by copying all the database files (cold backup) to TEST1
- Start the database on TEST1
- Change the IP addresses (on TEST2 and TEST1) OR the DNS, so that the clients find the database on TEST1
- On test2, change the startup type of OracleServiceORA from “automatic” to “manual”
- Re-activate the Rsync tasks (Orabackup and Oraarchives)
- De-activate the backup task
HA niveau 2 - Oracle 11g Cross platform Active Standby - Windows Primary database and Linux Active Standby
This note describes the procedure of configuring a cross platform using the 11g RMAN Active Duplicate as well as an Active Standby Database setup over a Windows and Linux platform.
The Metalink note Data Guard Support for Heterogeneous Primary and Physical Standbys in Same Data Guard Configuration [ID 413484.1] describes the supported cross platform combinations between a primary and standby database.
The environment used is as follows:
Primary
Windows 7 64 bit
11g Release 2
DB_UNIQUE_NAME=orcl
Active Standby
Oracle Enterprise Linux 5.7 64 bit
11g Release 2
DB_UNIUE_NAME=orcl_dr
- Add static entry in listener.ora
(SID_DESC =
(GLOBAL_DBNAME =orcl_dr)
(ORACLE_HOME =/u02/app/oracle/product/11.2.0/dbhome_1 )
(SID_NAME =orcl_dr)
)-
Reload listener or stop and start listener
-
Add entries in tnsnames.ora on both source and target
ORCL_DR=
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = linux01.gavinsoorma.com)(PORT = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = orcl_dr)
)
)
ORCL =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = gavin-pc)(PORT = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = orcl)
)
)-
Create password file on target - ensure same password is used the primary database password file
-
Create directory for audit _file_dest
-
Create directory for database files
On the Windows server the datafile location is C:\ORADATA|ORCL. On the Linux machine the corresponding location is '/u01/oradata/orcl_dr'
-
Create directory for log_archive_dest_1 - '/u01/oradata/orcl_dr/arch/'
-
Create init.ora in $ORACLE_HOME /dbs location with one entry
*.DB_NAME=orcl_dr-
STARTUP NOMOUNT the standby database
-
This is the RMAN command used to create a Duplicate from Active Database :
(Note the db_file_name_convert and log_file_name_convert parameters)
DUPLICATE TARGET DATABASE
FOR STANDBY
FROM ACTIVE DATABASE
NOFILENAMECHECK
DORECOVER
SPFILE
SET DB_UNIQUE_NAME="orcl_dr"
SET AUDIT_FILE_DEST="/u02/app/oracle/admin/orcl_dr/adump"
SET DIAGNOSTIC_DEST="/u02/app/oracle"
SET LOG_ARCHIVE_DEST_2="service=orcl_dr LGWR SYNC REGISTER VALID_FOR=(online_logfile,primary_role)"
SET FAL_SERVER="orcl_dr"
SET FAL_CLIENT="orcl"
SET CONTROL_FILES='/u01/oradata/orcl_dr/control01.ctl','/u01/oradata/orcl_dr/control02.ctl','/u01/oradata/orcl_dr/control03.ctl'
SET DB_FILE_NAME_CONVERT='C:\ORADATA\ORCL\','/u01/oradata/orcl_dr/'
SET LOG_FILE_NAME_CONVERT='C:\ORADATA\ORCL\','/u01/oradata/orcl_dr/';Note - the mistake I made here was not setting the parameters LOG_ARCHIVE_DEST_1 and LOG_ARCHIVE_FORMAT in the above RMAN Duplicate script
That is why we will see archive log files being created on the target like :
/u02/app/oracle/product/11.2.0/dbhome_1/dbs/c:oradataorclarchARC0000000005_0765492451.0001
So, remember to add SET LOG_ARCHIVE_DEST_1 and SET LOG_ARCHIVE_FORMAT for correct paths and names.
-
From the Primary database run the following command :
c:\app\gavin\product\11.2.0\dbhome_2\BIN>rman target sys/oracle11g auxiliary sys/oracle11g@orcl_dr- ON PRIMARY
SQL> alter system set standby_file_management=AUTO scope=both;
System altered.
SQL> alter system set fal_server=orcl scope=both;
System altered.
SQL> alter system set fal_client=orcl_dr scope=both;
System altered.
SQL> alter system set LOG_ARCHIVE_DEST_2='SERVICE=orcl_dr LGWR SYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) NET_TIMEOUT=60 DB_UNIQUE_NAME=orcl_dr' scope=both;- ON STANDBY
SQL> alter system set LOG_ARCHIVE_DEST_1='LOCATION=/u01/oradata/orcl_dr/arch VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=orcl_dr';SQL>
System altered.
SQL> alter system set LOG_ARCHIVE_DEST_2='SERVICE=orcl LGWR SYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=orcl' scope=both;
System altered.-
Shutdown and open the Standby database and configure the Real Time Apply (Active Data Guard)
SQL> shutdown immediate;
ORA-01109: database not open
Database dismounted.
ORACLE instance shut down.
SQL> startup;
ORACLE instance started.
Total System Global Area 835104768 bytes
Fixed Size 2217952 bytes
Variable Size 230688800 bytes
Database Buffers 595591168 bytes
Redo Buffers 6606848 bytes
Database mounted.
Database opened.
SQL> recover managed standby database using current logfile disconnect;
Media recovery complete
SQL> select platform_name,open_mode from v$database;
PLATFORM_NAME OPEN_MODE
------------------------------------------------------------ --------------------
Linux x86 64-bit READ ONLY.HA niveau 2 - Standby database logical from physical with RMAN from active database
Basé principalement sur http://www.oracledistilled.com/oracle-database/high-availability/data-guard/creating-a-physical-standby-using-rman-duplicate-from-active-database/
Physical standby : https://oracle-base.com/articles/11g/data-guard-setup-11gr2
On ne peut pas créer directement une LOGICAL STANDBY avec RMAN. Il faut d’abord créer une PHYSICAL STANDBY, puis la convertir en LOGICAL.
PHYSICAL STANDBY
Primary database informations :
Host: ocm1.odlabs.net
DB_NAME = pritst
DB_UNIQUE_NAME=pritst
Standby database information :
Host: ocm2.odlabs.net
DB_NAME = pritst
DB_UNIQUE_NAME = stbytst
LE DB_UNIQUE_NAME DE LA STANDBY EST DONC DIFFERENT. Ce paramètre n’est pas modifié sur tous les tutos relatif aux standby databases. Cependant Oracle précise :
"A database in an Oracle Data Guard environment is uniquely identified by means of the DB_UNIQUE_NAME parameter in the initialization parameter file. The DB_UNIQUE_NAME must be unique across all the databases with the same DBID for RMAN to work correctly in an Oracle Data Guard environment."
NOTE : la Standard Edition dispose bien de Dataguard mais pas du Managed Standby (envoi et application automatique des archives par Oracle). Ce n'est disponible que dans l'Enterprise (avec option payante !). La procédure ci-dessous s'applique donc à une version Enterprise.
Pour une Standard Edition, il faudra copier manuellement les archives vers la Standby, puis les appliquer également manuellement (par un script à intervalles réguliers, par exemple).
SUR LA PRIMARY
1. La base doit être en ARCHIVELOG FORCE_LOGGING
SQL> select log_mode,force_logging from v$database;
SQL> alter database force logging;2. Doubler les REDO LOGS par des STANDBY REDO LOGS de taille identiques, mais créer un groupe de plus que les REDO standards
SQL> select group#, thread#, bytes/1024/1024 from v$log;
SQL> alter database add standby logfile '/u01/app/oracle/oradata/pritst/stby_redo01.log' size 50M;
SQL> alter database add standby logfile '/u01/app/oracle/oradata/pritst/stby_redo02.log' size 50M;
SQL> alter database add standby logfile '/u01/app/oracle/oradata/pritst/stby_redo03.log' size 50M;
SQL> alter database add standby logfile '/u01/app/oracle/oradata/pritst/stby_redo04.log' size 50M;3. Vérifier les DB_*_NAME...
SQL> show parameter db_name
db_name string pritst
SQL> show parameter db_unique_name
db_unique_name string pritst...Et indiquer le DB_UNIQUE_NAME dans LOG_ARCHIVE_CONFIG
SQL> show parameter LOG_ARCHIVE_CONFIG
log_archive_config string
SQL> alter system set log_archive_config='DG_CONFIG=(pritst,stbytst)';4. Modifier LOG_ARCHIVE_DEST_1 et LOG_ARCHIVE_DEST_2
SQL> show parameter log_archive_dest_1
log_archive_dest_1 string LOCATION=/u01/app/oracle/oradata/pritst/arch
SQL> alter system set LOG_ARCHIVE_DEST_1='LOCATION=/u01/app/oracle/oradata/pritst/arch/ VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=pritst';
SQL> alter system set LOG_ARCHIVE_DEST_STATE_1=ENABLE;
SQL> alter system set LOG_ARCHIVE_DEST_STATE_2=DEFER; # enable it ONLY after creating logical standby
SQL> show parameter LOG_ARCHIVE_DEST_2
log_archive_dest_2 string
SQL> alter system LOG_ARCHIVE_DEST_2='SERVICE=DESTTST LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=stbytst';
-- Attention : nom TNS de la base standby dans "SERVICE"
SQL> alter system set LOG_ARCHIVE_MAX_PROCESSES=16; # it should be between 4 and 30Rappel :
Sur Standard Edition, l'archive_dest_2 ne fonctionne pas sur la primary, mais en copiant les archives à la main et en appliquant :
SQL> recover standby database;
il rejoue alors les archives présentes. Cette procédure manuelle fonctionne donc pour la standby, même si c'est pour une Enterprise.
Par contre attention sur une Standard si LOG_ARCHIVE_DEST_2 a été paramétré, la primary remplit ses traces car elle ne sait pas envoyer les archives automatiquement ! On peut paramétrer LOG_ARCHIVE_DEST_STATE_2=DEFER (comme indiqué ci-dessus) en attendant.
5. FAL_SERVER est la base primary et FAL_CLIENT est la standby.
SQL> alter system set fal_server=pritst;
SQL> alter system set fal_client=stbytst;6. Il faut logguer les ajouts/suppression de fichiers aussi
SQL> alter system set standby_file_management=auto;* NOTE : tout ça (et même plus) peut éventuellement être ajouté dans un bloc RUN de RMAN :
run {
sql channel prmy1 "alter system set log_archive_config=''DG_CONFIG=(pritst,stbytst)''";
sql channel prmy1 "alter system set log_archive_dest_2=''SERVICE=stbytst LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=stbytst''";
sql channel prmy1 "alter system set log_archive_max_processes=5";
sql channel prmy1 "alter system set fal_client=stbytst";
sql channel prmy1 "alter system set fal_server=pritst";
sql channel prmy1 "alter system set standby_file_management=AUTO";
sql channel prmy1 "alter system set log_archive_dest_state_1=enable";
sql channel prmy1 "alter system archive log current";
sql channel stby "alter database recover managed standby database using current logfile disconnect from session";
}7. Et s'assurer que le REMOTE LOGING est activé
(rappel : password file créé par : orapwd file=orapwtestgg1 password=test entries=5)
SQL > show parameter password
SQL > alter system set remote_login_passwordfile=exclusive;8. LISTENER : les bases doivent être gérée STATIQUEMENT. Ajouter aux 2 listerner.ora :
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(SID_NAME = pritst)
(ORACLE_HOME = /u01/app/oracle/product/11.2.0/dbhome_1)
)
)9. Ajouter les 2 bases aux tnsnames des 2 serveurs
SOURCETST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = ocm1.odlabs.net)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = pritst)
)
)
DESTTST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = ocm2.odlabs.net)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = pritst)(UR=A)
# attention : le listener prend le DB_UNIQUE_NAME si la base n'est pas définie statiquement.
# « UR=A » nécessaire car la secondary démarrée en NOMOUNT n'acceptera pas les connexions ("BLOCKED" au lsnrctl status). Ce paramètre permet de passer outre.
)
)SUR LA SECONDARY
1.préparer le terrain pour RMAN
* Note : penser au sysctl.conf si pas déjà fait par l’installation d’Oracle
- Soit manuellement :
Créer l'arborescence :
[oracle@ocm2 ~]$ mkdir oradata
[oracle@ocm2 ~]$ mkdir oradata/pritst
[oracle@ocm2 ~]$ mkdir oradata/pritst/arch
[oracle@ocm2 ~]$ mkdir /u01/app/oracle/admin
[oracle@ocm2 ~]$ mkdir /u01/app/oracle/admin/pritst
[oracle@ocm2 ~]$ mkdir /u01/app/oracle/admin/pritst/adump
[oracle@ocm2 ~]$ mkdir /u01/app/oracle/admin/pritst/bdump
[oracle@ocm2 ~]$ mkdir /u01/app/oracle/admin/pritst/dpdump
[oracle@ocm2 ~]$ mkdir /u01/app/oracle/admin/pritst/pfileet ajouter dans /etc/oratab :
pritst:/u01/app/oracle/product/11.2.0/dbhome_1:N- OU simplement en créant une base identique à la primary, vide.
2. Créer un LISTENER (si base créée manuellement), et enregistrer statiquement la standby
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(SID_NAME = pritst)
(ORACLE_HOME = /u01/app/oracle/product/11.2.0/dbhome_1)
)
)
$ lsnrctl start3. S'assurer que TNS connaît bien les 2 bases par tnsping
4. Créer un init.ora basique
$ cat initpritst.ora
DB_NAME=pritst
DB_UNIQUE_NAME=stbytstsi base a été créée par dbca, crée le pfile à partir du spfile :
SQL> create pfile from spfile ;et y modifier DB_UNIQUE_NAME, supprimer le spfile et redémarrer la base en NOMOUNT.
5. recopier le password file du primary (important : il ne faut pas le recréer mais reprendre celui du primary)
$ scp oracle@ocm1:$ORACLE_HOME/dbs/orapwpritst $ORACLE_HOME/dbs6. Lancer la base en NOMOUNT
La base démarre avec le PFILE si on s’est assuré que le spfile a bien été supprimé.
Sortir de la session sqlplus ensuite pour ne pas bloquer RMAN
$ sqlplus / as sysdba
Connected to an idle instance.
SQL> startup nomount
SQL> exit7. fichier de commande de réplication RMAN (toujours sur la standby) dupstby.cmd
run {
allocate channel pri1 type disk;
allocate channel pri2 type disk;
allocate channel prmy4 type disk;
allocate auxiliary channel stby type disk;
duplicate target database
for standby
from active database
dorecover
spfile
set db_unique_name='stbytst'
set control_files='/u01/app/oracle/oradata/pritst/control01.ctl','/u01/app/oracle/oradata/pritst/control02.ct'
set fal_client='pritst'
set fal_server='stbytst'
set standby_file_management='AUTO'
set log_archive_config='dg_config=(pritst,stbytst)'
set log_archive_dest_1='LOCATION=/u01/app/oracle/oradata/pritst/arch/ VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=stbytst'
set log_archive_dest_2='service=sourcetst ASYNC valid_for=(ONLINE_LOGFILE,PRIMARY_ROLE) db_unique_name=pritst'
nofilenamecheck;
}
* Noter l'inversion de pritst et stbytst dans log_archive_dest_1 et log_archive_dest_2
* Si l'arborescence n'est pas la même que sur le primary, ajouter :
set db_file_name_convert='<chemin des fichiers PRYMARY>','<chemin des fichiers SECONDARY>'
set log_file_name_convert='<chemin des fichiers PRYMARY>','<chemin des fichiers SECONDARY>'8. se connecter aux 2 bases pour lancer le script
* S'assurer que chacun des serveurs se connecte à la base de l'autre via TNS avec SYS
* Si la secondary n'a pas été mise en archivelog par dbca, le répertoire archive n'existe peut-être pas ! Créer le même que dans le paramètre LOG_ARCHIVE_DEST_1 qui arrivera de la primary, et vérifier les droits !
* LA BASE PRIMAIRE DOIT AVOIR ETE DEMARREE AVEC UN SPFILE, sinon RMAN refuse de lancer la duplication !
$ rman
Recovery Manager: Release 11.2.0.1.0 - Production on Fri Jul 13 16:47:46 2012
Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved.
RMAN> connect target sys/password@SOURCETST
connected to target database: PRITST (DBID=3720300117)
RMAN> connect auxiliary sys/password@DESTTST
connected to auxiliary database: PRITST (not mounted)OU :
$ rman target sys/password@SOURCETST auxiliary sys/password@DESTTST* NOTE : en cas de plantage de RMAN, après correction de l’erreur, penser à supprimer le spfile qui a pu être créé juste avant le plantage
RMAN> @dupstby.cmd9. A la fin de la duplication, lancer le processus de recovery
$ sqlplus / as sysdba
SQL> alter database recover managed standby database disconnect from session;en cas d'erreur ORA-01153 :
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE DISCONNECT FROM SESSION;
SQL> exit10. Vérifier l’application des REDO LOGS (via les ARCHIVE LOGS)
SQL> select sequence#, first_time, next_time, applied from v$archived_log order by sequence#;en forçant sur la PRIMARY un switch :
SQL> alter system switch logfile;Optionnel
Choisir le niveau de sécurité sur la PRIMARY (MAXIMUM PERFORMANCE par défaut)
SQL> SELECT protection_mode FROM v$database;
MAXIMUM PERFORMANCEChoisir un des modes :
Maximum Performance // Default
Transactions on the primary commit as soon as redo information has been written to the online redo log. Transfer of redo information to the standby server is asynchronous.
SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_2='SERVICE=stbytst NOAFFIRM ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=stbytst';
SQL> ALTER DATABASE SET STANDBY DATABASE TO MAXIMIZE PERFORMANCE;Maximum Availability
Transactions on the primary do not commit until redo information has been written to the online redo log and the standby redo logs of at least one standby location. If no standby location is available, it acts in the same manner as maximum performance mode until a standby becomes available again.
SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_2='SERVICE=stbytst AFFIRM SYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=stbytst';
SQL> ALTER DATABASE SET STANDBY DATABASE TO MAXIMIZE AVAILABILITY;Maximum Protection
Transactions on the primary do not commit until redo information has been written to the online redo log and the standby redo logs of at least one standby location.If not suitable standby location is available, the primary database shuts down.
SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_2='SERVICE=DESTTST AFFIRM SYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=stbytst';
SQL> SHUTDOWN IMMEDIATE;
SQL> STARTUP MOUNT;
SQL> ALTER DATABASE SET STANDBY DATABASE TO MAXIMIZE PROTECTION;
SQL> ALTER DATABASE OPEN;READ-ONLY STANDBY
On peut passer une base PHYSICAL STANDBY momentanément en READ ONLY afin de l’interroger.
SQL>alter database recover managed standby database cancel;
SQL>alter database open read only;
SQL>select open_mode from v$database;
SQL>alter database recover managed standby database using current logfile disconnect;
SQL>select open_mode from v$database;
-- doit indiquer "READ ONLY WITH APPLY"REDEMARRAGE DE LA STANDBY :
-- Start the database:
SQL> STARTUP NOMOUNT;
-- Mount the standby database:
SQL> ALTER DATABASE MOUNT STANDBY DATABASE;
-- Start the managed recovery operation:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION;CONVERSION PHYSICAL EN LOGICAL STANDBY
Basé sur :
https://chenguangblog.wordpress.com/2011/02/09/creating-logical-standby-database/
https://docs.oracle.com/cd/E11882_01/server.112/e41134/create_ls.htm#SBYDB4737
http://rajiboracle.blogspot.fr/2017/01/how-to-convert-physical-standby-to.html
Après création d’une physical standby avec RMAN, vérifier si des types sont incompatibles avec standby dans la base source :
SQL> select OWNER, TABLE_NAME, COLUMN_NAME, ATTRIBUTES, DATA_TYPE from dba_logstdby_unsupported;Eventuellement, convertir ou modifier les types incompatibles.
1. Sur la PRIMARY, créer un répertoire archive supplémentaire (utilisé si la primary est switchée en standby)
mkdir /u01/oradata/orcl/stbyarchives2. Modifier LOG_ARCHIVE_DEST_1 uniquement pour les REDO primary (ONLINE_LOGFILES), et créer un LOG_ARCHIVE_DEST_3 utilisé si la base switche en standby
SQL> alter system set log_archive_dest_1='LOCATION=/u01/app/oracle/oradata/pritst/arch/ VALID_FOR=(ONLINE_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=pritst';
SQL> alter system set LOG_ARCHIVE_DEST_3='LOCATION=/u01/app/oracle/oradata/orcl/stbyarchives VALID_FOR=(STANDBY_LOGFILES,STANDBY_ROLE)';3. Stopper et redémarrer au moins une fois la standby après création
SQL> shutdown immediate;
SQL> startup nomount;
SQL> alter database mount standby database;
SQL> alter database recover managed standby database disconnect from session;4. S'assurer que les logs sont au même niveau sur les 2 bases
SQL> select sequence#, first_time, next_time, applied from v$archived_log order by sequence#;5. Sur la standby, stopper le processus managed recovery
SQL> alter database recover managed standby database cancel;6. Sur la primary, lancer la construction des tables LogMiner pour le dictionnaire
SQL> begin
dbms_logstdby.build;
end;
/7. Sur la standby, lancer la conversion en LOGICAL
SQL> alter database recover to logical standby STBYORCL; # DB_UNIQUE_NAME de la standby* Si problème, stopper le processus dans une autre session par :
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;8. Générer quelques log switchs sur la primary pour s’assurer que les archives sont créées et envoyées vers la standby
SQL> alter system switch logfile;9. Sur la standby, la commande « alter database... » se termine après un certain temps.
En cas d’erreur :
ERROR at line 1:
ORA-20000: File /u01/app/oracle/oradata/pritst/temp01.dbf has wrong dbid or
dbname, remove or restore the offending file.
(qui n’est pas bloquante), recréer tout de suite le tablespace TEMP.
La base est désormais une LOGICAL STANDBY, on peut le voir dans l’alert.log :
RFS[12]: Identified database type as 'logical standby'
10. Relancer la standby
SQL> shutdown immediate
SQL> startup mount
SQL> alter database open resetlogs;11. Sur la standby, paramétrer un LOG_ARCHIVE_DEST_3 utilisé si la base switche en primary
SQL> alter system set LOG_ARCHIVE_DEST_3='LOCATION=/u01/app/oracle/oradata/orcl/stbyarchives VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE)';12. Il reste à lancer le processus SQL Apply
SQL> alter database start logical standby apply immediate;Désormais les changements détectés dans les ARCHIVE sont rejoués en SQL, la base est par ailleurs ouverte pour d’autres requêtes, même de modifications.
HA niveau 2 - Standby database manuelle (cold) sur Standard Edition (linux)
Sur le serveur primaire
Mettre sur la base primaire le paramètre STANDBY_FILE_MANAGEMENT à AUTO (sinon Oracle ne sait pas recréer des fichiers sur la standby, lors de création de tablespaces ou d'ajout de fichiers) :
SQL> connect / as sysdba
SQL> alter system set standby_file_management = AUTO;Passer la base primary en archive log :
alter system set log_archive_dest_1='LOCATION=/oradata01/ORCL/archives';
shutdown immediate;
startup mount;
alter database archivelog;
alter database open;Tester :
alter system switch logfile;vérifier que l'archive log se crée au bon endroit.
Sauvegarde à froid complète de la base primary :
shutdown immediate;
tar -cvzf /oradata01/ORCL.tgz /oradata01/ORCLSauvegarde du controlfile en mode standby :
startup
alter database create standby controlfile as '/oradata01/ctrlstdby.ctl' ;(c'est ce qui fera que la standby sera marquée « PHYSICAL STANDBY » et acceptera les recover des archive logs)
Synchronisation des archive logs
Mettre en place une copie des fichiers d'archives par rsync (qui les transfèrera à intervalles réguliers) :
1. Pour que ssh ne demande plus de mot de passe entre le primary et le standby :
créer une clé ssh sur le primary : ssh-keygen -t dsa (tout par défaut, sans passphrase)
copier la clé publique (contenue dans /home/oracle/.ssh/id_dsa.pub)
créer sur la serveur standby un fichier /home/oracle/.ssh/authorized_keys, et y coller la clé
2. Créer un script (à planifier à interval régulier, toutes les minutes par exemple) (/oracle/product/10.2.0/db_1/admin/ORCL/scripts/send_archives.sh ):
#!/bin/sh
rsync -e ssh -a --delete /oradata01/ORCL/archives/* 172.16.1.22:/oradata01/ORCL/archives 2>/dev/nullSur la database standby
Transférer le .tgz et le .ctl vers standby (par scp).
Paramétrer log_archives_dest_1 vers le répertoire qui recevra les archive log du primary.
Arrêter la base.
écraser la base existante :
cd /oradata01
tar -xvzf ORCL.tgzdupliquer (par cp) le ctrlstdby.ctl en control01.ctl, control02.ctl, control03.ctl.
script shell de démarrage de la base standby (/oracle/product/10.2.0/db_1/admin/ORCL/scripts/start_standby.sh) :
#!/bin/sh
. /home/oracle/.bashrc
export ORACLE_SID=ORCL
sqlplus / as sysdba << EOF
startup nomount;
alter database mount standby database;
exit
EOFscript sql d'application des logs (à planifier à intervalle régulier avec « >/dev/null 2>&1 ») (/oracle/product/10.2.0/db_1/admin/ORCL/scripts/apply_archive.sh) :
#!/bin/sh
. /home/oracle/.bashrc
export ORACLE_SID=ORCL
sqlplus / as sysdba << EOF
recover automatic standby database;
#Insérer un retour chariot dans le script avant « exit » sinon il attend indéfiniment
exit
EOFNote 1 : les messages d'info qui s'affichent lors du recover sont aussi loggués dans le fichier alert_ORCL.log. Penser à le remettre à zéro de temps en temps.
Note 2 : les fichiers archivelogs ne sont pas supprimés après leur application. Penser à faire le ménage dans le répertoire d'archives.
Switch standby en primary
Pour passer la standby en primary (/oracle/product/10.2.0/db_1/admin/ORCL/scripts/standby_to_primary.sh) :
#!/bin/sh
. /home/oracle/.bashrc
export ORACLE_SID=ORCL
sqlplus / as sysdba << EOF
alter database activate standby database;
alter database open;
exit
EOFla standby devient alors PRIMARY et refusera les recover (si on oublie d'enlever le script planifié, les erreurs seront logguées dans l'alert.log).
L'ancienne primary devra être remontée en standby mais pas de "switch back" possible.
On peut aussi arrêter la base passée en primary, la copier sur la machine reconstruite (donc "remettre" la primary sur la bonne machine) et recommencer la procédure pour refaire une standby sur la machine 2.
HA niveau 2 - Standby database manuelle (cold) sur Windows - Std Edition (services et tâches planifiées)
Sur Windows, l'automatisation du démarrage de la base standby et de l'application des archives est un peu plus compliquée que sous linux.
Ci-dessous, le serveur primaire sera SERVER1 et le secondaire SERVER2.
La base s'appellera ORCL.
Création des bases
sur SERVER1
Créer la base primaire avec les archivelogs activés, faire une sauvegarde à froid et générer un standby control file (Standby database manuelle (cold) sur Standard Edition), la transférer sur SERVER2.
sur SERVER2
Créer la base à l'identique. Arrêter ensuite la base et écraser les fichiers avec la sauvegarde venant de SERVER1. Les control files seront remplacés par le standby control file.
Modifier la clé de registre AUTOSTART
La standby ne doit pas démarrer en "OPEN" mais en "RECOVER". Il faut modifier son mode de démarrage automatique.
Lancer REGEDIT, trouver le registre :
HKLM/SOFTWARE/ORACLE/Key_Ora10gDB_home1La clé a la forme ORA_{DB_NAME}_AUTOSTART (ici ORA_ORCL_AUTOSTART). Double-cliquer sur cette clé et la mettre à « FALSE ». Ne pas fermer REGEDIT, on en aura besoin plus tard.
Créer le service de lancement de la standby
Il faut maintenant créer un service spécifique qui lancera automatiquement la base Standby. Commencer par télécharger 2 utilitaires, INSTSRV et SRVANY. Ils se trouvent dans le kit de ressources techniques, ou bien ici :
http://www.inscripta.net/ressources/articl...tion/srvany.zipCréer un service "OracleStandbyORCL" avec INSTSRV, service qui utilisera la commande SRVANY :
"C:\<répertoire utilitaires>\instsrv" OracleStandbyORCL "C:\<répertoire utilitaires>\srvany"Vérifier dans le gestionnaire de service qu'il est bien créé.
Copier le code ci-dessous dans un fichier "ORCL.REG", EN REMPLACANT "ORACLE_SID" par le nom de la base ("ORCL" ici), l'utilisateur qui lancera le service, ainsi que le chemin du script qui lancera la base dans la clé Parameters :
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\OracleStandbyORACLE_SID]
"Type"=dword:00000010
"Start"=dword:00000002
"ErrorControl"=dword:00000001
"ImagePath"=hex(2):45,00,3a,00,5c,00,6f,00,72,00,61,00,63,00,6c,00,65,00,5c,00,\
70,00,72,00,6f,00,64,00,75,00,63,00,74,00,5c,00,31,00,30,00,2e,00,32,00,2e,\
00,30,00,5c,00,64,00,62,00,5f,00,31,00,5c,00,42,00,49,00,4e,00,5c,00,73,00,\
72,00,76,00,61,00,6e,00,79,00,2e,00,65,00,78,00,65,00,00,00
"DisplayName"="OracleStandbyORACLE_SID"
"ObjectName"="Administrateur"
"DependOnService"=hex(7):4f,00,72,00,61,00,63,00,6c,00,65,00,53,00,65,00,72,00,\
76,00,69,00,63,00,65,00,4f,00,52,00,41,00,43,00,4c,00,45,00,5f,00,53,00,49,\
00,44,00,00,00,00,00
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\OracleStandbyORACLE_SID\Parameters]
"AppDirectory"="\"C:\\<répertoire utilitaires>\""
"Application"="\"C:\\<répertoire utilitaires>\\start_standby.cmd\""
"AppParameters"="ORACLE_SID"
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\OracleStandbyORACLE_SID\Security]
"Security"=hex:01,00,14,80,b8,00,00,00,c4,00,00,00,14,00,00,00,30,00,00,00,02,\
00,1c,00,01,00,00,00,02,80,14,00,ff,01,0f,00,01,01,00,00,00,00,00,01,00,00,\
00,00,02,00,88,00,06,00,00,00,00,00,14,00,fd,01,02,00,01,01,00,00,00,00,00,\
05,12,00,00,00,00,00,18,00,ff,01,0f,00,01,02,00,00,00,00,00,05,20,00,00,00,\
20,02,00,00,00,00,14,00,8d,01,02,00,01,01,00,00,00,00,00,05,04,00,00,00,00,\
00,14,00,8d,01,02,00,01,01,00,00,00,00,00,05,06,00,00,00,00,00,14,00,00,01,\
00,00,01,01,00,00,00,00,00,05,0b,00,00,00,00,00,18,00,fd,01,02,00,01,02,00,\
00,00,00,00,05,20,00,00,00,23,02,00,00,01,01,00,00,00,00,00,05,12,00,00,00,\
01,01,00,00,00,00,00,05,12,00,00,00
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\OracleStandbyORACLE_SID\Enum]
"0"="Root\\LEGACY_ORACLESTANDBYORACLE_SID\\0000"
"Count"=dword:00000001
"NextInstance"=dword:00000001Double-cliquer sur le fichier, accepter la modification des registres.
Retourner dans REGEDIT, trouver la clé HKLM\SYSTEM\CurrentControlSet\Services\OracleStandbyORCL nouvellement créée. Modifier à droite la valeur "DependOnService" en double-cliquant dessus, par "OracleServiceORCL" (la clé est en Héxa dans le fichier texte ci-dessus et ne peut être modifiée qu'à posteriori).
Note : on voit dans la clé "OracleStandbyORCL" que c'est SRVANY qui est lancé, avec les paramètres de la sous-clé "Parameters" (nom du script de démarrage de la base et SID de la base à passer à ce script)
Supprimer la clé "Enum" à gauche, elle sera recréée par PnP avec une valeur correcte "LEGACYxxx" la première fois qu'on entrera dans les propriétés du service.
Quitter REGEDIT, et dans le gestionnaire de services afficher les propriétés de OracleStandbyORCL pour créer la clé Enum, en profiter pour vérifier les paramètres.
Stopper le service OracleServiceORCL s'il ne l'est pas déjà. Lancer le service OracleStandbyORCL, vérifier qu'il se lance sans erreur et qu'il relance bien le service OracleServiceORCL.
Lancer sqlplus en SYSDBA, et vérifier que la base est bien en mode STANDBY :
C:\> set ORACLE_SID=ORCL
C:\> sqlplus / as sysdba
SQL> select instance_name, status from v$instance;
INSTANCE_NAME STATUS
---------------- ---------------
ORCL MOUNTED
SQL> select database_role from v$database;
DATABASE_ROLE
----------------
PHYSICAL STANDBYModifier tout de suite le paramètre d'initialisation standby_file_management (sa valeur par défaut ne permet pas la re-création de tablespaces et de fichiers de données sur la standby lorsqu'ils sont créés sur la base primaire) :
alter system set standby_file_management=AUTO;Synchronisation des bases
sur SERVER1
Planifier une tâche de synchronisation des archivelogs entre les 2 serveurs
Le script "synchro_standby.cmd" utilise BLAT pour envoyer des mails d'alertes (Blat est téléchargeable sur http://www.blat.net) et lance d'autres scripts .cmd et .sql détaillés plus bas. Planifier ce script à intervalles réguliers, par exemple tous les 1/4 d'heures : ce sera la valeur maximale de décalage entre la base primaire et la base standby.
@echo off
:: Primary to Standby server synchronization
:: (copy Oracle archivelogs to the Standby server)
setlocal enableExtensions enableDelayedExpansion
:: ======================
:: replication parameters
:: ======================
SET ORACLE_SID=%1
SET _SOURCE_DIR=/cygdrive/c/oradata/%ORACLE_SID%/archives/
SET _DESTINATION_SERVER=SERVER2
SET _DESTINATION_DIR=archivestandby%ORACLE_SID%
SET _SCRIPTS_DIR=C:\<répertoire utilitaires>\synchro_standby
SET _LOG_DIR=%_SCRIPTS_DIR%\log
SET _SQLPLUS=C:\oracle\product\10.2.0\db_1\BIN\sqlplus.exe -L
:: =============================
:: mail notifications parameters
:: =============================
SET _MAIL_RESSOURCES_DIR=C:\<répertoire utilitaires>\mail_ressources
SET _MAIL_SERVER_INI=%_MAIL_RESSOURCES_DIR%\mail_server.ini
SET _MAIL_ADMINS_INI=%_MAIL_RESSOURCES_DIR%\mail_admins.ini
SET _MAIL_FROM_INI=%_MAIL_RESSOURCES_DIR%\mail_from.ini
SET _BLAT=%_MAIL_RESSOURCES_DIR%\blat.exe
:: construct prefix for log file with date and time
set _DATE_STR=
set _TIME_STR=
for /f "tokens=1-3 delims=/.- " %%a in ("%DATE:* =%") do set _DATE_STR=%%a-%%b-%%c
for /f "tokens=1-3 delims=:," %%a in ("%TIME:* =%") do set _TIME_STR=%%a.%%b.%%c
SET _LOGFILE=%_DATE_STR%_%_TIME_STR%_%ORACLE_SID%_%~n0.log
:: timestamp for the log file
date /t > %_LOG_DIR%\%_LOGFILE% 2>&1
time /t >> %_LOG_DIR%\%_LOGFILE% 2>&1
:: test if parameters are initialized
IF "%ORACLE_SID%" == "" (
call :send_error_notification_to_admins "ERROR : %ORACLE_SID% Synchronization Problem" "script %~n0 : Parameter ORACLE_SID not initialized" >> %_LOG_DIR%\%_LOGFILE% 2>&1
goto END
)
:: Switch archive log file to copy last information to the Standby server
%_SQLPLUS% /nolog @%_SCRIPTS_DIR%\switchlog.sql >> %_LOG_DIR%\%_LOGFILE% 2>&1
IF NOT "%ERRORLEVEL%"=="0" (
call :send_error_notification_to_admins "ERROR : %ORACLE_SID% Switch archive log Problem" "script %~n0 : Problem during switching archive log" "%_LOG_DIR%\%_LOGFILE%" >> %_LOG_DIR%\%_LOGFILE% 2>&1
goto END
)
:: Synchronize archives to the Standby server
CALL %_SCRIPTS_DIR%\cwrsync.cmd %_SOURCE_DIR% %_DESTINATION_SERVER% %_DESTINATION_DIR% >> %_LOG_DIR%\%_LOGFILE% 2>&1
IF NOT "%ERRORLEVEL%"=="0" (
call :send_error_notification_to_admins "ERROR : %ORACLE_SID% Synchronization Problem" "script %~n0 : Synchronization problem between Primary and Standby Server" "%_LOG_DIR%\%_LOGFILE%" >> %_LOG_DIR%\%_LOGFILE% 2>&1
)
:END
endlocal
goto :eof
:: ===============================
:send_error_notification_to_admins
:: ===============================
:: Send an error notification to administrators
:: Parameters:
:: %1=subject
:: %2=body
:: %3=logfile (not required)
:: %4=logfile (not required)
SET _MAIL_SERVER=
FOR /F "eol=#" %%c in ('type %_MAIL_SERVER_INI%') do (
SET _MAIL_SERVER=%%c
)
SET _MAIL_FROM=
FOR /F "eol=#" %%c in ('type %_MAIL_FROM_INI%') do (
SET _MAIL_FROM=%%c
)
SET _MAIL_TO_ADMINS=
FOR /F "eol=#" %%c in ('type %_MAIL_ADMINS_INI%') do (
IF "!_MAIL_TO_ADMINS!" == "" (
SET _MAIL_TO_ADMINS=%%c
) else (
SET _MAIL_TO_ADMINS=!_MAIL_TO_ADMINS!,%%c
)
)
SET _BLAT_PARAMETERS=-body %2 -server %_MAIL_SERVER% -f %_MAIL_FROM% -t %_MAIL_TO_ADMINS% -subject %1
IF NOT "%3" == "" (
SET _BLAT_PARAMETERS=%_BLAT_PARAMETERS% -attach %3
)
IF NOT "%4" == "" (
SET _BLAT_PARAMETERS=%_BLAT_PARAMETERS% -attach %4
)
call %_BLAT% %_BLAT_PARAMETERS%
goto :eof
Il lance un premier script SQL "switchlog.sql' qui force un switch d'archivelog :
connect / as sysdba
alter system switch logfile;
exitpuis il lance un script DOS qui utilise CWRSYNC (http://sourceforge.net/projects/sereds/files/cwRsync/, portage CygWin de l'utilitaire RSYNC connu sous linux). RSYNC permet de synchroniser les répertoires d'archivelogs des deux serveurs en incrémental, sans devoir renvoyer tous les fichiers à chaque fois.
Il s'installe
- En tant que serveur sur SERVER2. Il crée un service qui lui permet de fonctionner en tâche de fond, et d'attendre les requêtes de SERVER1
- En tant que client sur SERVER1, qui enverra ses archivelogs vers SERVER2 par ce biais
Sur SERVER1, le script cwrsync.cmd est fourni lors de l'installation de CWRSYNC (dans le répertoire de celui-ci) à titre d'exemple. Il suffit de reprendre ce script, de vérifier les valeurs des variables au début, et d'ajouter à la fin du fichier :
SET _REP_SOURCE=%1
SET _SERV_DEST=%2
SET _REP_DEST=%3
rsync -arvz --delete %_REP_SOURCE% %_SERV_DEST%::%_REP_DEST%Les 3 paramètres lui seront passés par synchro_standby.cmd.
Paramétrer aussi les fichiers de configuration de Blat, dans C:\<répertoire utilitaires>\mail_ressources. Les .INI sont des fichiers texte, avec une valeur par ligne (respectivement nom du serveur SMTP, nom des destinataires des mails et nom de l'expéditeur).
sur SERVER2
Installer également CWRSYNC, en mode serveur. Editer le fichier rsyncd.conf dans le répertoire d'installation pour créer un point de partage :
use chroot = false
strict modes = false
hosts allow = *
log file = rsyncd.log
pid file = rsyncd.pid
[ArchiveStandbyORCL]
path = C:\oradata\ORCL\archives_temp
read_only = falseRelancer le service "RsyncServer" pour prendre en compte les modifications. NOTE : créer le répertoire C:\oradata\ORCL\archives_temp, qui recevra les archives de SERVER1. Ce répertoire reçoit temporairement les archivelogs, avant de les copier dans le "vrais" répertoire d'archive de la base et de les appliquer. On a ainsi, en cas d'erreur, une sauvegarde des archives. Ce répertoire étant synchronisé avec celui des archives de SERVER1, il suffit de faire un backup RMAN sur SERVER1 avec sauvegarde + suppression des archivelogs. Le vidage du répertoire sur SERVER1 videra automatiquement celui de SERVER2 à la synchronisation suivante.
Le script "apply_archive.cmd" applique les archivelogs dans la base standby. Il utilise lui aussi BLAT ainsi qu'un script SQL :
@echo off
:: Apply archives from Primary server in the Standby database
setlocal enableExtensions enableDelayedExpansion
:: ======================
:: replication parameters
:: ======================
SET ORACLE_SID=%1
SET _LASTARCHIVE=%2
SET _SCRIPTS_DIR=C:\<répertoire utilitaires>\apply_archive
SET _LOG_DIR=%_SCRIPTS_DIR%\log
SET _ARCHIVE_FROM_PRIMARY_DIR=C:\oradata\%ORACLE_SID%\archives_temp
SET _ARCHIVE_TO_APPLY_DIR=C:\oradata\%ORACLE_SID%\archives
SET _SQLPLUS=C:\oracle\product\10.2.0\db_1\BIN\sqlplus.exe -L
:: =============================
:: mail notifications parameters
:: =============================
SET _MAIL_RESSOURCES_DIR=C:\<répertoire utilitaires>\mail_ressources
SET _MAIL_SERVER_INI=%_MAIL_RESSOURCES_DIR%\mail_server.ini
SET _MAIL_ADMINS_INI=%_MAIL_RESSOURCES_DIR%\mail_admins.ini
SET _MAIL_FROM_INI=%_MAIL_RESSOURCES_DIR%\mail_from.ini
SET _BLAT=%_MAIL_RESSOURCES_DIR%\blat.exe
:: construct prefix for log file with date and time
set _DATE_STR=
set _TIME_STR=
for /f "tokens=1-3 delims=/.- " %%a in ("%DATE:* =%") do set _DATE_STR=%%a-%%b-%%c
for /f "tokens=1-3 delims=:," %%a in ("%TIME:* =%") do set _TIME_STR=%%a.%%b.%%c
SET _LOGFILE=%_DATE_STR%_%_TIME_STR%_%ORACLE_SID%_%~n0.log
:: timestamp for the log file
date /t > %_LOG_DIR%\%_LOGFILE% 2>&1
time /t >> %_LOG_DIR%\%_LOGFILE% 2>&1
:: apply archive from Primary server to Standby
%_SQLPLUS% /nolog @%_SCRIPTS_DIR%\apply_archive.sql >> %_LOG_DIR%\%_LOGFILE% 2>&1
IF NOT "!ERRORLEVEL!"=="0" (
call :send_error_notification_to_admins "ERROR : %ORACLE_SID% Synchronization Problem" "script %~n0 : Error in launching applying archives: SQL Plus Problem" "%_LOG_DIR%\%_LOGFILE%" >> %_LOG_DIR%\%_LOGFILE% 2>&1
goto END
)
:: extract waited archive file name from Log (ORA-00308)
SET _NEXTARCHIVE=
for /F "tokens=5 delims='\" %%a IN ('findstr /r /i /c:"ORA-00308" %_LOG_DIR%\%_LOGFILE%') do set _NEXTARCHIVE=%%a
echo Next Archive : %_NEXTARCHIVE% >> %_LOG_DIR%\%_LOGFILE% 2>&1
:: if file header is corrupted, ORA-00308 is not logged in the log file and no file name is provided
:: if the script cannot connect to the database and no file name is provided
IF "%_NEXTARCHIVE%" == "" (
call :send_error_notification_to_admins "ERROR : %ORACLE_SID% Synchronization Problem" "script %~n0 : Error in applying %_LASTARCHIVE% : File Header Problem OR Database Access Problem" "%_LOG_DIR%\%_LOGFILE%" >> %_LOG_DIR%\%_LOGFILE% 2>&1
goto END
)
:: if file is corrupted, the apply fails and the file name waited by standby database is always the same
IF "%_NEXTARCHIVE%" == "%_LASTARCHIVE%" (
call :send_error_notification_to_admins "ERROR : %ORACLE_SID% Synchronization Problem" "script %~n0 : Error in applying %_NEXTARCHIVE% : File Corrupted" "%_LOG_DIR%\%_LOGFILE%" >> %_LOG_DIR%\%_LOGFILE% 2>&1
goto END
)
:: copy the new archive logs and apply them into the Standy Database
IF EXIST %_ARCHIVE_FROM_PRIMARY_DIR%\%_NEXTARCHIVE% (
:: get archive file sended by primary server
copy /Y %_ARCHIVE_FROM_PRIMARY_DIR%\%_NEXTARCHIVE% %_ARCHIVE_TO_APPLY_DIR% >> %_LOG_DIR%\%_LOGFILE% 2>&1
:: call script recursively to apply archive log
echo === RECURSIVE CALL, AT LEAST ONE ARCHIVELOG === >> %_LOG_DIR%\%_LOGFILE% 2>&1
%_SCRIPTS_DIR%\apply_primary_archive.cmd %ORACLE_SID% %_NEXTARCHIVE%
:: delete the applyed archivelog
del /F /Q %_ARCHIVE_TO_APPLY_DIR%\%_NEXTARCHIVE% >> %_LOG_DIR%\%_LOGFILE% 2>&1
)
:END
endlocal
goto :eof
:: ===============================
:send_error_noticication_to_admins
:: ===============================
:: Send an error notification to administrators
:: Parameters:
:: %1=subject
:: %2=body
:: %3=logfile (not required)
:: %4=logfile (not required)
SET _MAIL_SERVER=
FOR /F "eol=#" %%c in ('type %_MAIL_SERVER_INI%') do (
SET _MAIL_SERVER=%%c
)
SET _MAIL_FROM=
FOR /F "eol=#" %%c in ('type %_MAIL_FROM_INI%') do (
SET _MAIL_FROM=%%c
)
SET _MAIL_TO_ADMINS=
FOR /F "eol=#" %%c in ('type %_MAIL_ADMINS_INI%') do (
IF "!_MAIL_TO_ADMINS!" == "" (
SET _MAIL_TO_ADMINS=%%c
) else (
SET _MAIL_TO_ADMINS=!_MAIL_TO_ADMINS!,%%c
)
)
SET _BLAT_PARAMETERS=-body %2 -server %_MAIL_SERVER% -f %_MAIL_FROM% -t %_MAIL_TO_ADMINS% -subject %1
IF NOT "%3" == "" (
SET _BLAT_PARAMETERS=%_BLAT_PARAMETERS% -attach %3
)
IF NOT "%4" == "" (
SET _BLAT_PARAMETERS=%_BLAT_PARAMETERS% -attach %4
)
call %_BLAT% %_BLAT_PARAMETERS%
goto :eof
Il lance le script SQL "apply_archive.sql" :
connect / as sysdba
alter database recover automatic standby database;
exitParamétrer aussi les fichiers de configuration de Blat, dans C:\<répertoire utilitaires>\mail_ressources. Les .INI sont des fichiers texte, avec une valeur par ligne (respectivement nom du serveur SMTP, nom des destinataires des mails et nom de l'expéditeur).
TESTS
Sur SERVER1, lancer la tâche planifiée "synchro_standby", qui doit générer une archive et copier celle-ci sur SERVER2 sous archives_temp Sur SERVER2, lancer la tâche planifiée "apply_archive", qui doit intégrer l'archive. Vérifier les log du script, qui doivent ressembler à ceci :
12/08/2008 16:56 SQL*Plus: Release 10.2.0.4.0 - Production on Tue Aug 12 16:56:04 2008 Copyright (c) 1982, 2007, Oracle. All Rights Reserved. Connected. alter database recover automatic standby database * ERROR at line 1: ORA-00279: change 50345552 generated at 08/12/2008 16:51:03 needed for thread 1 ORA-00289: suggestion : F:\E2TSW\ARCHIVES\ARC00162_0662457568.001 ORA-00280: change 50345552 for thread 1 is in sequence #162 ORA-00278: log file 'F:\E2TSW\ARCHIVES\ARC00162_0662457568.001' no longer needed for this recovery ORA-00308: cannot open archived log 'F:\E2TSW\ARCHIVES\ARC00162_0662457568.001' ORA-27041: unable to open file OSD-04002: unable to open file O/S-Error: (OS 2) The system cannot find the file specified. Disconnected from Oracle Database 10g Release 10.2.0.4.0 - Production Next Archive : ARC00162_0662457568.001
Les messages d'erreur sont "normaux". Le numéro d'archive indiqué sur l'ORA-00278 et à la fin du log soit être supérieur de 1 par rapport aux archiveslogs existants dans archive_temp : c'est la prochaine archive attendue de SERVER1.
HA niveau 2 - Standby database manuelle par RMAN (hot) sur Standard Edition
Sur le serveur standby
Créer l'instance sur le serveur standby (on suppose la même arborescence et le même nom de base sur les 2 serveurs).
Une fois créée, la lancer :
$ sqlplus "/ as sysdba"
SQL> startup nomountSur le serveur primaire
Lancer rman, faire un backup de la base avec le control file pour la standby :
backup database include current controlfile for standby ;
sql "alter system archive log current";
backup archivelog allCopier les fichiers de backup vers le serveur standby, dans le même répertoire.
Créer une entrée pour la base standby dans le tnsnames.ora du serveur primaire. Lancer RMAN et se connecter aux 2 bases (local=primaire, distante=standby) :
$ rman
RMAN> connect auxiliary sys/password@standbydb
RMAN> connect target /Lancer la duplication :
duplicate target database for standby dorecover nofilenamecheck;En cas d'erreur :
RMAN> connect auxiliary sys/password@standbydb
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-04006: error from auxiliary database: ORA-12528: TNS:listener: all
appropriate instances are blocking new connectionsAjouter les lignes suivantes (en rouge) au listener.ora du serveur standby :
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(SID_NAME = PLSExtProc)
(ORACLE_HOME = C:\oracle\product\10.2.0\db_1)
(PROGRAM = extproc)
)
(SID_DESC =
(SID_NAME = DBSID)
(ORACLE_HOME = C:\oracle\product\10.2.0\db_1)
)
)L'erreur :
starting media recovery
Oracle Error:
ORA-01547: warning: RECOVER succeeded but OPEN RESETLOGS would get error below
ORA-01152: file 1 was not restored from a sufficiently old backup
ORA-01110: data file 1: '/oradata/DBID/SYSTEM01.DBF'
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: failure of Duplicate Db command at 11/08/2010 21:07:42
RMAN-03015: error occurred in stored script Memory Script
RMAN-06053: unable to perform media recovery because of missing log
RMAN-06025: no backup of log thread 1 seq 17200 lowscn 14557604 found to restore
RMAN-06025: no backup of log thread 1 seq 17199 lowscn 14557397 found to restorepeut n'être qu'un warning. Relancer la standby et tester le recover d'un archive log :
SQL> alter database mount standby database;
SQL> recover standby database
ORA-00279: change 57953 generated at ....
ORA-00289: suggestion : ....
ORA-00280: change 57953 ....
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}Si l'archive demandée est présente (en générer un à partir du serveur primaire au besoin) et qu'appuyer sur "Entrée" suffit à l'appliquer : tout va bien !
HA niveau 3 - Standby DataGuard database sur 11g Enterprise Edition
La création d'un base Standby en Enterprise Edition est à peu près identique à celle sur une base Standard Edition, à ceci prêt que c'est une option payante... Et qu'on peut activer la réplication automatique, contrairement à la version gratuite SE.
Contexte :
Primary database :
Host: ocm1.odlabs.net
DB_NAME = PRITST
DB_UNIQUE_NAME=PRITST
Standby database :
Host: ocm2.odlabs.net
DB_NAME = PRITST
DB_UNIQUE_NAME = STDBYTST
Préparation de la réplication
Préparation de la base primaire
Vérifier que la base primaire est bien démarrée et configurée ! Puis effectuer les actions suivantes sur la base primaire pour qu’elle soit capable de communiquer et d’échanger avec la base standby.
Activez la force logging
[ocm1.odlabs.net]$ sqlplus / as sysdba
SQL> alter database force logging; Ajoutez les standby logfiles
Doubler les REDO LOGS par des STANDBY REDO LOGS de taille identiques, mais créer un groupe de plus que les REDO standards :
SQL> select group#, thread#, bytes/1024/1024 from v$log;
SQL> alter database add standby logfile '/u01/app/oracle/oradata/pritst/stby_redo01.log' size 50M;
SQL> alter database add standby logfile '/u01/app/oracle/oradata/pritst/stby_redo02.log' size 50M;
SQL> alter database add standby logfile '/u01/app/oracle/oradata/pritst/stby_redo03.log' size 50M;
SQL> alter database add standby logfile '/u01/app/oracle/oradata/pritst/stby_redo04.log' size 50M;Paramètre log_archive_config
Ce paramètre est permet d’activer la fonctionnalité de la data Guard, il accepte en argument les db_unique_name de base primaire et secondaire (standby) :
SQL> alter system set log_archive_config='dg_config=(pritst,stbytst)';Paramètre log_archive_dest_2
SQL> alter system set log_archive_dest_2='service=OEMR_STBY LGWR async valid_for=(online_logfiles,primary_role) db_unique_name=stbytst';Paramètre standby_file_management
Ce paramètre apporte automatiquement les modifications sur la base de secours lorsqu’un fichier de données a été ajouté ou supprimé sur la base primaire (fal_server), il permet aussi à la base primaire d’être prête à changer le rôle primaire à standby et vice-et-versa.
SQL> alter system set standby_file_management = AUTO scope=both ;Paramètre REMOTE_LOGIN_PASSWORDFILE
Vérifiez que le paramètre REMOTE_LOGIN_PASSWORDFILE est positionné à la valeur EXCLUSIVE. Sinon exécuter cette commande :
SQL> alter system set remote_login_passwordfile=exclusive scope=spfile;Activez l’archivage
SQL> archive log list ;
-- S'il n'est pas "Enabled" :
SQL> shutdown immediate
SQL> startup mount
SQL> alter database archivelog;
SQL> alter database open;Ajouter une entrée pour la base standby dans le tnsnames.ora du serveur primaire
STDBYTST=
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = ocm2.odlabs.net)(PORT = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = PRITST)
)
)Tester :
[ocm1.odlabs.net]$ tnsping STDBYTST
Attempting to contact (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = ocm2.odlabs.net)(PORT = 1521))) (CONNECT_DATA = (SERVER = DEDICTED) (SERVICE_NAME = STDBYST)))
OK (20 msec)Copier le tnsnames.ora et le fichier passwd vers la base standby
[ocm1.odlabs.net]$ scp orapwpritst oracle@ocm2.odlabs.net:/u01/app/oracle/product/db/11.2.0.3/dbs/
Préparation de la base de secours (standby)
Sur ce serveur on a juste installé le software Oracle 11gR2 et on a que le fichier mot de passe et le tnsnames.ora copiés de la base primaire.
Création de listener dans $ORACLE_HOME/network/admin
LISTENER =
(ADDRESS_LIST=
(ADDRESS=(PROTOCOL=tcp)(HOST=ocm2.odlabs.net)(PORT=1521)))
)
ADR_BASE_LISTENER = /u01/app/oracle
INBOUND_CONNECT_TIMEOUT_LISTENER=120
DIAG_ADR_ENABLED_LISTENER=OFF
SUBSCRIBE_FOR_NODE_DOWN_EVENT_LISTENER=OFF
# Enregistrement statique auprès de Listener (l’enregistrement dynamique laisse la base inaccessible pendant un certain, d’où la nécessité de forcer l'enregistrement statique)
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(GLOBAL_NAME = STDBYTST)
(ORACLE_HOME = /u01/app/oracle/product/db/11.2.0.3/)
(SID_NAME = PRITST)
)
)Tester le bon fonctionnement de tnsnames.ora
[ocm2.odlabs.net]$ tnsping STDBYTST
Attempting to contact (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = ocm2.odlabs.net)(PORT = 1521))) (CONNECT_DATA = (SERVER = DEDICTED) (SERVICE_NAME = STDBYTST)))
OK (0 msec)
[ocm2.odlabs.net]$ tnsping PRITST
Attempting to contact (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = ocm1.odlabs.net)(PORT = 1521))) (CONNECT_DATA = (SERVICE_NAME = PRITST)))
OK (10 msec)Création des répertoires de données et d’archivage (la structure physique qui va accueillir la base de données)
(A adapter selon l'arborescence du serveur primaire)
[ocm2.odlabs.net]$ mkdir -p /data01/ORADATA/pritst
[ocm2.odlabs.net]$ mkdir -p /archlog_primaire/ORADATA/pritst
[ocm2.odlabs.net]$ cd /u01/app/oracle/admin
[ocm2.odlabs.net]$ mkdir pritst; cd pritst
[ocm2.odlabs.net]$ mkdir pfile adump bdump cdump udumpCréation du fichier d'initialisation init.ora pour la base standby
[ocm2.odlabs.net]$ cd $ORACLE_HOME/dbs
[ocm2.odlabs.net]$ echo DB_NAME=pritst> initpritst.oraLancer la base de données en mode nomount
[ocm2.odlabs.net]$ su - oracle
[ocm2.odlabs.net]$ sqlplus sys/Passw0rd@STDBYTST as sysdba
SQL> startup nomount pfile='initpritst.ora' ;Duplication de la base de production par RMAN
Préparation du script RMAN duplicate duplicate_pritst.rman
run {
allocate auxiliary channel stdbytst type disk;
allocate channel pritst_1 device type disk;
allocate channel pritst_2 device type disk;
allocate channel pritst_3 device type disk;
allocate channel pritst_4 device type disk;
duplicate target database for standby from active database NOFILENAMECHECK
spfile
set control_files='/data01/ORADATA/pritst/control01.ctl','/data01/ORADATA/pritst/control02.ctl',
'/data01/ORADATA/pritst/control03.ctl'
set db_unique_name='STDBYTST'
set audit_file_dest='/u01/app/oracle/admin/pritst/adump'
set db_domain=''
set diagnostic_dest='/u01/app/oracle'
set log_archive_max_processes='5'
set fal_client='STDBYTST'
set fal_server='PRITST'
set standby_file_management='AUTO'
set log_archive_config='dg_config=(PRITST,STDBYTST)'
set log_archive_dest_2='service=RMAP LGWR ASYNC valid_for=(ONLINE_LOGFILE,PRIMARY_ROLE) DB_UNIQUE_NAME=PRITST'
;
}Lancer la duplication
[ocm2.odlabs.net]$ rman target sys/Passw0rd@PRITST auxiliary sys/Passw0rd@STDBYTST
RMAN>@duplicate_pritst.rmanActivation de la réplication
Actions sur la base standby
Démarrage du processus Redo Apply
[ocm2.odlabs.net]$ sqlplus sys/Passw0rd@STDBYTST as sysdba
SQL> alter database recover managed standby database using current logfile disconnect from session;
SQL> select sequence#,first_time,applied from v$archived_log order by 1;
SEQUENCE# FIRST_TI APPLIED
---------- -------- ---------
1446 07/02/13 YES
1447 07/02/13 YESVérifier le status de la base standby
SQL> select open_mode,database_role from v$database;
OPEN_MODE DATABASE_ROLE
-------------------- ----------------
MOUNTED PHYSICAL STANDBYTester l'application des archives sur la standby
Sur la base primaire :
[ocm1.odlabs.net]$ sqlplus / as sysdba
SQL> ALTER SYSTEM SWITCH LOGFILE;
SQL> ALTER SYSTEM SWITCH LOGFILE;Sur la base standby, vérifier que 2 nouvelles archives ont été appliquées :
[ocm2.odlabs.net]$ sqlplus / as sysdba
SQL> SELECT SEQUENCE#, FIRST_TIME, NEXT_TIME, APPLIED FROM V$ARCHIVED_LOG ORDER BY SEQUENCE#;Post Installation
Le choix du mode de protection
Il y a trois modes de protection de données :
- Maximum Availability
- Maximum Performance
- Maximum Protection
Chaque mode nécessite une configuration particulière pour sa mise en œuvre.
https://docs.oracle.com/database/121/SBYDB/protection.htm#SBYDB02000
HA niveau 4 - RAC database 10g sur Enterprise Edition
Composants de RAC
Dans le cadre d’un cluster RAC, la couche cluster peut être gérée par une couche logicielle provenant de fournisseurs tiers :
- Sun Cluster
- IBM HACMP
- Veritas Cluster ...
Oracle fournit sa propre couche cluster dénommée Cluster Ready Services ou CRS (ClusterWare depuis la version 10g)
Les processus principaux
L’ensemble de processus constituant le CRS est composé :
- de 3 processus d’arrière plans (CRS, CSS et EVM)
- d’un ensemble de processus supplémentaires gérant la communication avec les autres couches du cluster (Base de données, applications etc.)
NB : Sous Windows, les processus sont des threads rattachés au processus oracle.exe.
le processus CRS
Le processus CRS (CRS pour Cluster Ready Services) est la brique maîtresse du clusterWare Oracle. C’est ce processus qui gère les opérations de haute disponibilité dans le cluster. Le CRS gère l’ensemble des applications intégrées au cluster (Database, instance, service, listener etc.) définies et référencées dans l’OCR (cf définition plus loin).
Le CRS détecte les changements d’états de ressources. C’est le processus CRS qui redémarre automatiquement les ressources en cas de faute. Et ce, si la définition de la ressource dans l’OCR l’en autorise.
- Ce processus est propriété de l’utilisateur root.
- Son démarrage est piloté dans l’inittab du serveur par des scripts d’init.
- Il redémarre automatiquement en cas d’arrêt.
- Sous unix, il apparait dans la liste des processus sous le nom : crsd.bin
Par défaut, les fichiers de journaux et de trace de ce processus sont stockés dans : $CRS_HOME/log/$HOSTNAME/crsd/crsd.log
le processus CSS
Le processus CSS (CSS pour Cluster Synchronisation Services) gère la configuration du cluster dans l’évolution de l’appartenance (et de la non-appartenance) des noeuds au cluster.
C’est ce processus qui informe les autres noeuds la présence de nouveau noeud, ou du retrait d’anciens noeuds.
- Ce processus est propriété de l’utilisateur oracle
- Son démarrage est piloté dans l’inittab du serveur par des scripts d’init.
- Son arrêt inopiné engendre le redémarrage du noeud.
- Sous unix, il apparait dans la liste des processus sous le nom : ocssd.bin
Par défaut, les fichiers de journaux et de trace de ce processus sont stockés dans : $CRS_HOME/log/$HOSTNAME/cssd/ocssd.log
le processus EVM
Le processus EVM (EVM pour EVent Management) enregistre tous les événements enregistrés dans le cluster. Ce processus va publier les événements que le CRS génère. Pour cela, il va enregistrer ces événements dans le répertoire du logger ($CRS_HOME/evm/log) et exécuter (via le processus evmlogger, fils du processus evmd) les appels demandés.
- Ce processus est propriété de l’utilisateur oracle
- Son démarrage est piloté dans l’inittab du serveur par des scripts d’init.
- Sous unix, il apparait dans la liste des processus sous le nom : evmd.bin.
Par défaut, les fichiers de journaux et de trace de ce processus sont stockés dans : $CRS_HOME/log/$HOSTNAME/evmd/log/evmd.log
Les fichiers d’événements sont dans $CRS_HOME/evm/log
Les processus annexes
OPROCD
Oprocd est un processus résident en mémoire. Ce processus surveille le cluster et réalise le "fencing" du cluster, (le Fencing est un isolement primitif d’un noeud lors d’une défaillance de celui-ci.). Lors de ce fencing, oprocd effectue des vérifications de fonctionnement, puis se fige. Si le reveil de l’OProcd n’a pas lieu avant une durée configurée, celui-ci procède au redémarrage du noeud du cluster.
RACG
Les processus RACG étendent le fonctionnement du clusterWare aux besoins des produits Oracle.
ONS (Oracle Notification Service)
ONS est un service simple fonctionnement en PUSH permettant la diffusion de message à tous les noeuds du cluster.
Les fichiers ou disques de gestion
le registre du cluster ou Oracle Cluster Registry ou OCR
Le registre du cluster ou OCR est un fichier ou disque partagé du cluster qu’il convient de sécuriser (réplication baie, multiplexage).
Cet OCR contient la définition des éléments constitutifs du cluster ainsi que leur état.
On y trouvera entre autres : la définition noeuds, les interfaces réseaux, les adresses VIP, les bases de données, la définition et le paramétrage des ressources, leur dépendances etc etc.
Ce fichier est mis à jour automatiquement lorsque l’administrateur utilise les outils de configurations comme srvctl, crs_register, crsctl).
On obtient les informations sur l’OCR par la commande ocrcheck :
$ $CRS_HOME/bin/ocrcheck
Status of Oracle Cluster Registry is as follows :
Version : 2
Total space (kbytes) : 513652
Used space (kbytes) : 5152
Available space (kbytes) : 508500
ID : 1318599504
Device/File Name : /dev/rdsk/c3t8d0s1
Device/File integrity check succeeded
Device/File Name : /dev/rdsk/c4t10d0s1
Device/File integrity check succeeded
Cluster registry integrity check succeededNB : Lorsqu’on reconfigure un service comme vu dans cet article , on modifie directement les entrées de la ressource définie dans l’OCR
Le disque votant ou Voting Disk
Le disque votant est un périphérique disque partagé permettant de gérer l’appartenance au cluster. De ce fait, il est intimement lié au processus CSS. De plus, il permet les arbitrage d’appartenance au cluster lorsque tous les liens d’interconnexions sont rompus.
On obtient les informations des disques votant avec la commande crsctl :
$ $CRS_HOME/bin/crsctl query css votedisk
0. 0 /dev/rdsk/c3t8d0s3
1. 0 /dev/rdsk/c4t10d0s3
2. 0 /dev/rdsk/c3t9d0s3
located 3 votedisk(s).Il est recommandé de multiplexer de manière impaire le disque votant. Si il est unique, alors la redondance du support devra être assurée (par une baie, ou tout autre mécanisme).
Sa taille est d’environ 50Mo par fichier.
Principes
Sur les noeuds du cluster
Certains éléments sont spécifiques à chaque noeud du cluster, d'autres son partagés par tous.
Stockage
Les noeuds (2 ou plus) disposent chacun, individuellement, des binaires Oracle, ainsi que des fichiers d'initialisation (PFILE ou SPFILE selon la configuration de départ).
Tous les noeuds partagent les disques OCR et Voting Disk. Ils partagent également les disques de données (où sont stockés les fichiers des bases en cluster).
Adresses réseau
Chaque serveur dispose de 3 adresses réseau : Une adresse publique sur le réseau local, utilisée pour accéder à la machine en dehors d'Oracle Une adresse virtuelle (VIP), dans la même plage d'adresse du réseau local, initialisée par Oracle lorsque le cluster démarre, utilisée par les clients Oracle pour accéder aux bases en RAC (cf plus bas configuration des clients) Une adresse privée, dédiée au lien entre les noeuds du cluster. Cette adresse est dans une plage non utilisée sur le réseau local ; le lien peut passer par le réseau (non conseillé) ou être un lien croisé (entre deux noeuds) ou un « mini »-réseau dédié entre plusieurs noeuds.
Listeners
Deux modes sont disponibles, sans être exclusifs (les deux peuvent être activés simultanément) :
- FAILOVER (TAF : Transparent Application Failover)
Oracle RAC propose le FAILOVER en configurant un listener par noeud du cluster afin de gérer les requêtes de connexion à un même service (un service représente une base de données enregistrée auprès des listener du cluster). Si un noeud ou une interconnexion échoue, l'adresse IP virtuelle (VIP) est réallouée à un noeud survivant, permettant la notification de panne rapide aux clients connectés par cette VIP. Si le client (ET l'application) sont compatibles et configurés pour le TAF, le client est reconnecté à un noeud actif.
- LOAD BALANCING
Oracle RAC propose l'équilibrage de charge en distribuant les connexions entre les DISPATCHERS des noeuds du cluster, qui eux-même répartissent ces requêtes sur les instances des bases en cluster des noeuds les moins chargés.
Plusieurs LISTENER sont donc déclarés, au moins un par noeud. Chaque noeud connait son propre LISTENER et les LISTENER des autres noeuds. Exemple de configuration sur le premier noeud d'un cluster :
LISTENER_RAC1=
(DESCRIPTION_LIST =
(DESCRIPTION=
(ADDRESS = (PROTOCOL = TCP)(HOST = rac1-vip)(PORT = 1521)(IP = FIRST))
(ADDRESS = (PROTOCOL = TCP)(HOST = rac2-vip)(PORT = 1521)(IP = FIRST)))
SID_LIST_LISTENER_RAC1=
(SID_LIST=
(SID_DESC=
(SID_NAME=)
(ORACLE_HOME=/u01/app/oracle/11/db_1)
Il en va de même pour les clients.
Sur les clients
Le tableau suivant résume les options disponibles pour le TNSNAMES.ORA (le client doit obligatoirement être en version 10g minimum).
| Option | Parameter Setting |
| Try each address, in order, until one succeeds | FAILOVER=on |
| Try each address, randomly, until one succeeds Note: This option is not enabled if Use Options Compatible with Net8 8.0 Clients is selected in Oracle Net Manager. |
LOAD_BALANCE=on FAILOVER=on |
| Try one address, selected at random Note: This option is not enabled if Use Options Compatible with Net8 8.0 Clients is selected in Oracle Net Manager. |
LOAD_BALANCE=on |
| Use each address in order until destination reached | SOURCE_ROUTE=on |
| Use only the first address Note: This option is not enabled if Use Options Compatible with Net8 8.0 Clients is selected in Oracle Net Manager. |
LOAD_BALANCE=off FAILOVER=off SOURCE_ROUTE=off |
TAF (Transparent Application Failover)
Exemples de configuration (source : http://download.oracle.com/docs/cd/B28359_01/network.111/b28316/advcfg.htm) :
Example: TAF with Connect-Time Failover and Client Load Balancing
Implement TAF with connect-time failover and client load balancing for multiple addresses. In the following example, Oracle Net connects randomly to one of the protocol addresses on sales1-server or sales2-server. If the instance fails after the connection, the TAF application fails over to the other node's listener, reserving any SELECT statements in progress.
sales.us.example.com=
(DESCRIPTION=
(LOAD_BALANCE=on)
(FAILOVER=on)
(ADDRESS=
(PROTOCOL=tcp)
(HOST=sales1-server)
(PORT=1521))
(ADDRESS=
(PROTOCOL=tcp)
(HOST=sales2-server)
(PORT=1521))
(CONNECT_DATA=
(SERVICE_NAME=sales.us.example.com)
(FAILOVER_MODE=
(TYPE=select)
(METHOD=basic))))
Example: TAF Retrying a Connection
TAF also provides the ability to automatically retry connecting if the first connection attempt fails with the RETRIES and DELAY parameters. In the following example, Oracle Net tries to reconnect to the listener on sales1-server. If the failover connection fails, Oracle Net waits 15 seconds before trying to reconnect again. Oracle Net attempts to reconnect up to 20 times.
sales.us.example.com=
(DESCRIPTION=
(ADDRESS=
(PROTOCOL=tcp)
(HOST=sales1-server)
(PORT=1521))
(CONNECT_DATA=
(SERVICE_NAME=sales.us.example.com)
(FAILOVER_MODE=
(TYPE=select)
(METHOD=basic)
(RETRIES=20)
(DELAY=15))))
Example: TAF Pre-Establishing a Connection
A backup connection can be pre-established. The initial and backup connections must be explicitly specified. In the following example, clients that use net service name sales1.us.example.com to connect to the listener on sales1-server are also preconnected to sales2-server. If sales1-server fails after the connection, Oracle Net fails over to sales2-server, preserving any SELECTstatements in progress. Likewise, Oracle Net preconnects to sales1-server for those clients that use sales2.us.example.com to connect to the listener on sales2-server.
sales1.us.example.com=
(DESCRIPTION=
(ADDRESS=
(PROTOCOL=tcp)
(HOST=sales1-server)
(PORT=1521))
(CONNECT_DATA=
(SERVICE_NAME=sales.us.example.com)
(INSTANCE_NAME=sales1)
(FAILOVER_MODE=
(BACKUP=sales2.us.example.com)
(TYPE=select)
(METHOD=preconnect))))
sales2.us.example.com=
(DESCRIPTION=
(ADDRESS=
(PROTOCOL=tcp)
(HOST=sales2-server)
(PORT=1521))
(CONNECT_DATA=
(SERVICE_NAME=sales.us.example.com)
(INSTANCE_NAME=sales2)
(FAILOVER_MODE=
(BACKUP=sales1.us.example.com)
(TYPE=select)
(METHOD=preconnect))))
LOAD BALANCING
Exemples de configuration (même source que ci-dessus) :
The following example shows a TNSNAMES.ORA file configured for client load balancing:
sales.us.example.com=
(DESCRIPTION=
(ADDRESS_LIST=
(LOAD_BALANCE=on)
(ADDRESS=(PROTOCOL=tcp)(HOST=sales1-server)(PORT=1521))
(ADDRESS=(PROTOCOL=tcp)(HOST=sales2-server)(PORT=1521)))
(CONNECT_DATA=
(SERVICE_NAME=sales.us.example.com)))
The following example shows a tnsnames.ora file configured for connect-time failover:
sales.us.example.com= (DESCRIPTION= (ADDRESS_LIST= (LOAD_BALANCE=off) (FAILOVER=ON) (ADDRESS=(PROTOCOL=tcp)(HOST=sales1-server)(PORT=1521)) (ADDRESS=(PROTOCOL=tcp)(HOST=sales2-server)(PORT=1521))) (CONNECT_DATA=(SERVICE_NAME=sales.us.example.com)))
Installation
L'installation sera documentée avec les éléments suivants :
- 2 noeuds dans le cluster (« rac1 » et « rac2 »), serveur 64 bits
- chaque noeud est un serveur sous Linux CentOS 5 x86_64
- le cluster est géré par Clusterware d'Oracle 10g
- ils disposent chacun d'un disque interne, et de 4 disques partagés par des liens fibre
- Les disques partagés sont gérés par ASM (Automatique Storage Management) d'Oracle, au dessus de partitions RAW DEVICE.
- les réseau publiques et VIP sont dans la plage 10.1.86
- le réseau privé est dans la plage 192.168.1
- On se connectera « root » dans un premier temps pour paramétrer le système.
IMPORTANT : CentOS n'étant pas officiellement reconnu par Oracle, il faut « faire passer » le système pour un RedHat. Editer le fichier /etc/redhat-release et remplacer le contenu par « redhat-4 » sur tous les noeuds du futur cluster.
Obtenir les logiciels
Les logiciels suivants seront utilisés :
- Oracle 10g (10.2.0.1) CRS (10201_clusterware_linux_x86_64.zip)
- Oracle DB software (10201_database_linux_x86_64.zip)
- Oracle patch upgrade to 10.2.0.4 (p6810189)
Clusterware et Oracle Database seront donc en version 10.2.0.4 à la fin de l'installation.
IMPORTANT : S'assurer qu'on dispose des versions correspondant au système : 32 ou 64 bits !
Configurer les disques partagés
Les disques partagés sont gérés sur les deux serveurs par les outils MULTIPATH compatibles avec les liens fibres multiples.
Après différents tests, la procédure correcte de configuration est la suivante.
Vérifier que les disques sont visibles sur les 2 serveurs.
Commande multipath sur le noeud 1 :
multipath -ll
mpath3 (36006016009c12200a2307179ff5cdf11) dm-10 DGC,RAID 5
[size=20G][features=1 queue_if_no_path][hwhandler=1 emc][rw]
\_ round-robin 0 [prio=2][active]
\_ 2:0:1:3 sdj 8:144 [active][ready]
\_ 3:0:1:3 sdv 65:80 [active][ready]
\_ round-robin 0 [prio=0][enabled]
\_ 2:0:0:3 sdd 8:48 [active][ready]
\_ 3:0:0:3 sdp 8:240 [active][ready]
mpath2 (36006016009c12200902740c0ff5cdf11) dm-9 DGC,RAID 5
[size=10G][features=1 queue_if_no_path][hwhandler=1 emc][rw]
\_ round-robin 0 [prio=2][active]
\_ 2:0:0:2 sdc 8:32 [active][ready]
\_ 3:0:0:2 sdo 8:224 [active][ready]
\_ round-robin 0 [prio=0][enabled]
\_ 2:0:1:2 sdi 8:128 [active][ready]
\_ 3:0:1:2 sdu 65:64 [active][ready]
mpath1 (36006016009c1220056b037e9fe5cdf11) dm-8 DGC,RAID 5
[size=20G][features=1 queue_if_no_path][hwhandler=1 emc][rw]
\_ round-robin 0 [prio=2][active]
\_ 2:0:0:1 sdb 8:16 [active][ready]
\_ 3:0:0:1 sdn 8:208 [active][ready]
\_ round-robin 0 [prio=0][enabled]
\_ 2:0:1:1 sdh 8:112 [active][ready]
\_ 3:0:1:1 sdt 65:48 [active][ready]
mpath4 (36006016009c122008c806e0f005ddf11) dm-11 DGC,RAID 5
[size=10G][features=1 queue_if_no_path][hwhandler=1 emc][rw]
\_ round-robin 0 [prio=2][active]
\_ 2:0:1:4 sdk 8:160 [active][ready]
\_ 3:0:1:4 sdw 65:96 [active][ready]
\_ round-robin 0 [prio=0][enabled]
\_ 2:0:0:4 sde 8:64 [active][ready]
\_ 3:0:0:4 sdq 65:0 [active][ready]Commande multipath sur le noeud 2 :
multipath -ll
mpath2 (36006016009c12200a2307179ff5cdf11) dm-9 DGC,RAID 5
[size=20G][features=1 queue_if_no_path][hwhandler=1 emc][rw]
\_ round-robin 0 [prio=2][active]
\_ 2:0:1:3 sdh 8:112 [active][ready]
\_ 3:0:1:3 sdp 8:240 [active][ready]
\_ round-robin 0 [prio=0][enabled]
\_ 2:0:0:3 sdd 8:48 [active][ready]
\_ 3:0:0:3 sdl 8:176 [active][ready]
mpath0 (36006016009c12200902740c0ff5cdf11) dm-7 DGC,RAID 5
[size=10G][features=1 queue_if_no_path][hwhandler=1 emc][rw]
\_ round-robin 0 [prio=2][active]
\_ 2:0:0:1 sdb 8:16 [active][ready]
\_ 3:0:0:1 sdj 8:144 [active][ready]
\_ round-robin 0 [prio=0][enabled]
\_ 2:0:1:1 sdf 8:80 [active][ready]
\_ 3:0:1:1 sdn 8:208 [active][ready]
mpath3 (36006016009c1220056b037e9fe5cdf11) dm-6 DGC,RAID 5
[size=20G][features=1 queue_if_no_path][hwhandler=1 emc][rw]
\_ round-robin 0 [prio=2][active]
\_ 2:0:0:0 sda 8:0 [active][ready]
\_ 3:0:0:0 sdi 8:128 [active][ready]
\_ round-robin 0 [prio=0][enabled]
\_ 2:0:1:0 sde 8:64 [active][ready]
\_ 3:0:1:0 sdm 8:192 [active][ready]
mpath1 (36006016009c122008c806e0f005ddf11) dm-8 DGC,RAID 5
[size=10G][features=1 queue_if_no_path][hwhandler=1 emc][rw]
\_ round-robin 0 [prio=2][active]
\_ 2:0:1:2 sdg 8:96 [active][ready]
\_ 3:0:1:2 sdo 8:224 [active][ready]
\_ round-robin 0 [prio=0][enabled]
\_ 2:0:0:2 sdc 8:32 [active][ready]
\_ 3:0:0:2 sdk 8:160 [active][ready] Les périphériques sont visibles à la fois en tant que /dev/mpath/mpathXX, et /dev/dm-XX.
On voit cependant que les disques ne correspondent pas, sur les deux serveurs, aux mêmes numéros de périphériques mpath. Par exemple, le disque partagé ayant l'identifiant « 36006016009c12200902740c0ff5cdf11 » est reconnu comme « mpath2 » sur le noeud 1, et « mpath0 » sur le noeud 2.
Afin de faciliter l'administration, il convient tout d'abord de renommer les périphériques mpath. Dans /etc/multipath.conf, ajouter un bloc « multipaths » avec une déclaration « multipath » par périphérique à renommer, en s'appuyant sur les IDs repérés avec « multipath -ll » .
Exemple sur le noeud 1 :
multipaths {
multipath {
# mpath2 = dm-9 = OCR
wwid 36006016009c12200902740c0ff5cdf11
alias ocr1
}
multipath {
# mpath1 = dm-8 = ASM1
wwid 36006016009c1220056b037e9fe5cdf11
alias asm1
}
multipath {
# mpath4 = dm-11 = VOTING
wwid 36006016009c122008c806e0f005ddf11
alias voting1
}
multipath {
# mpath3 = dm-10 = ASM2
wwid 36006016009c12200a2307179ff5cdf11
alias asm2
}
}
Le noeud 2 sera configuré de la même façon, avec les IDs correspondants.
Après redémarrage, « multipath -ll » donnera sur le noeud 1 :
multipath -ll
asm2 (36006016009c12200a2307179ff5cdf11) dm-10 DGC,RAID 5
[size=20G][features=1 queue_if_no_path][hwhandler=1 emc][rw]
...
ocr1 (36006016009c12200902740c0ff5cdf11) dm-9 DGC,RAID 5
[size=10G][features=1 queue_if_no_path][hwhandler=1 emc][rw]
...
asm1 (36006016009c1220056b037e9fe5cdf11) dm-8 DGC,RAID 5
[size=20G][features=1 queue_if_no_path][hwhandler=1 emc][rw]
...
voting1 (36006016009c122008c806e0f005ddf11) dm-11 DGC,RAID 5
[size=10G][features=1 queue_if_no_path][hwhandler=1 emc][rw]
...Les périphériques sont vus désormais dans /dev/mpath/<LIBELLE>.
Créer des partitions sur ces disques. Sur un des deux noeuds, lancer fdisk sur chaque périphérique.
Exemple pour OCR1 sur rac1 :
fdisk /dev/mpath/ocr1
The number of cylinders for this disk is set to 1305.
There is nothing wrong with that, but this is larger than 1024,
and could in certain setups cause problems with:
1) software that runs at boot time (e.g., old versions of LILO)
2) booting and partitioning software from other OSs
(e.g., DOS FDISK, OS/2 FDISK)
Command (m for help): p
Disk /dev/mpath/ocr1: 10.7 GB, 10737418240 bytes
255 heads, 63 sectors/track, 1305 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-1305, default 1):
Using default value 1
Last cylinder or +size or +sizeM or +sizeK (1-1305, default 1305):
Using default value 1305
Command (m for help): p
Disk /dev/mpath/ocr1: 10.7 GB, 10737418240 bytes
255 heads, 63 sectors/track, 1305 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/mpath/ocr1p1 1 1305 10482381 83 Linux
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 22: Invalid argument.
The kernel still uses the old table.
The new table will be used at the next reboot.
Syncing disks.L'erreur à l'écriture de la table de partitions est dûe au fait que fdisk gère mal le multipath. Cependant, les partitions doivent apparaître dans /dev/mpath, sous le nom des périphériques auxquels sont ajoutés le numéro de partition créée (ici, « p1 ») :
ls -l /dev/mpath
total 0
...
lrwxrwxrwx 1 root root 7 Oct 21 12:37 asm1 -> ../dm-8
lrwxrwxrwx 1 root root 8 Oct 21 12:37 asm1p1 -> ../dm-15
lrwxrwxrwx 1 root root 8 Oct 21 12:37 asm2 -> ../dm-10
lrwxrwxrwx 1 root root 8 Oct 21 12:37 asm2p1 -> ../dm-13
lrwxrwxrwx 1 root root 7 Oct 21 12:37 ocr1 -> ../dm-9
lrwxrwxrwx 1 root root 8 Oct 21 12:37 ocr1p1 -> ../dm-14
lrwxrwxrwx 1 root root 8 Oct 21 12:37 voting1 -> ../dm-11
lrwxrwxrwx 1 root root 8 Oct 21 12:37 voting1p1 -> ../dm-16Créer les RAW DEVICES
Oracle crée ses volumes ASM obligatoirement au-dessus de disques en raw device.
Editer le fichier /etc/sysconfig/rawdevices sur chaque noeud, et ajouter :
/dev/raw/raw1 /dev/mapper/ocr1p1
/dev/raw/raw2 /dev/mapper/voting1p1
/dev/raw/raw3 /dev/mapper/asm1p1
/dev/raw/raw4 /dev/mapper/asm2p1Relancer le service rawdevices (qui exécute des commandes « raw » en fonction de la configuration de /etc/sysconfig/rawdevices), et vérifier qu'il sera relancé au prochain redémarrage :
service rawdevices restart
chkconfig --level 2345 rawdevices onEditer /etc/rc.local pour donner les bon propriétaire et droits à ces devices. Ajouter :
chown oracle.oinstall /dev/raw/raw1
chown oracle.oinstall /dev/raw/raw2
chown oracle.oinstall /dev/raw/raw3
chown oracle.oinstall /dev/raw/raw4
chmod 600 /dev/raw/raw1
chmod 600 /dev/raw/raw2
chmod 600 /dev/raw/raw3
chmod 600 /dev/raw/raw4On ne peut pas lancer manuellement ces commandes pour l'instant car l'utilisateur « oracle » et le groupe « oinstall » n'existent pas forcément sur ces serveurs, tant qu'oracle n'a pas été installé.
Par contre, il convient d' « initialiser » ces raw devices pour s'assurer qu'Oracle trouvera des partitions vierges (l'installation peut échouer pratiquement à la fin s'il y a un doute à la création de l'OCR et du Voting Disk). La commande
dd if=/dev/zero of=/dev/raw/raw1lancée sur chacun des raw devices évite ce désagrément.
Préparer le système d'exploitation
Sur chacun des noeuds, commencer par supprimer les logiciels inutiles (s'ils ne sont pas nécessaires à une autre application sur le serveur) et installer les logiciels et librairies requises.
yum remove –purge openoffice* php* http* mysql*
yum update
yum install setarch* compat-libstdc++* make-3* glibc-2* openmotif* compat-db-4* gcc compat-gcc* glibc-devel-2* libaio-0*Si le serveur est en 64 bits, ajouter
yum install glibc-2*.i386 glibc-devel-2*.i386Editer le fichier /etc/hosts pour déclarer les adresses de tous les noeuds :
127.0.0.1 localhost.localdomain localhost
# Public IP address
10.1.86.2 rac1.localdomain rac1
10.1.86.3 rac2.localdomain rac2
#Private IP address
10.1.86.5 rac1-priv.localdomain rac1-priv
10.1.86.6 rac2-priv.localdomain rac2-priv
#Virtual IP address
192.168.1.1 rac1-vip.localdomain rac1-vip
192.168.1.2 rac2-vip.localdomain rac2-vipIMPORTANT : sur tous les noeuds du cluster, les interfaces doivent porter le même nom. Si l'adresse publique correspond à eth0 sur un noeud, elle devra correspondre à eth0 sur tous les noeuds. Idem pour les adresses privées et vip.
Dans le cas contraire, durant l'installation de ClusterWare, on aura une erreur :
Thrown when the IP address os a host cannot be determinedEditer le fichier /etc/sysctl.conf, vérifier ou ajouter les paramètres suivants :
kernel.shmall = 2097152
kernel.shmmax = 2147483648
kernel.shmmni = 4096
# semaphores: semmsl, semmns, semopm, semmni
kernel.sem = 250 32000 100 128
fs.file-max = 65536
net.ipv4.ip_local_port_range = 1024 65000
net.core.rmem_default=262144
net.core.rmem_max=262144
net.core.wmem_default=262144
net.core.wmem_max=262144Et appliquer ces paramètres :
# /sbin/sysctl -pEditer le fichier /etc/security/limits.conf, ajouter :
oracle soft nproc 2047
oracle hard nproc 16384
oracle soft nofile 1024
oracle hard nofile 65536 Editer (ou créer s'il n'existe pas) le fichier /etc/pam.d/login, y ajouter :
session required /lib/security/pam_limits.soDans le fichier /etc/selinux/config, s'assurer que SELinux est désactivé :
SELINUX=disabledLancer ou relancer le service ntp, et le configurer au démarrage
service ntpd restart
chkconfig --level 2345 ntpd onEt enfin paramétrer le module « hangcheck-timer » dans /etc/modprobe.conf, ajouter :
options hangcheck-timer hangcheck_tick=30 hangcheck_margin=180le charger pour la session en cours :
modprobe -v hangcheck-timerPréparer l'environnement Oracle
Créer les utilisateurs et groupes (l'utilisateur sera « oracle », répertoire personnel « /oracle ») :
groupadd oinstall
groupadd dba
groupadd oper
useradd -g oinstall -G dba -d /oracle oracle
passwd oracleet les répertoires (« crs » accueillera les binaires Clusterware, « db_1 » accueillera les binaires de Database Server) :
mkdir -p /oracle/product/10.2.0/crs
mkdir -p /oracle/product/10.2.0/db_1
mkdir -p /oradata
chown -R oracle.oinstall /oracle /oradataL'utilisateur étant créé, on peut exécuter les commandes du fichier rc.local :
/etc/rc.localConfigurer l'environnement de l'utilisateur. Editer /oracle/.bash_profile et ajouter :
# Oracle Settings
TMP=/tmp; export TMP
TMPDIR=$TMP; export TMPDIR
ORACLE_BASE=/u01/app/oracle; export ORACLE_BASE
ORACLE_HOME=$ORACLE_BASE/product/10.2.0/db_1; export ORACLE_HOME
ORACLE_SID=RAC1; export ORACLE_SID
ORACLE_TERM=xterm; export ORACLE_TERM
PATH=/usr/sbin:$PATH; export PATH
PATH=$ORACLE_HOME/bin:$PATH; export PATH
LD_LIBRARY_PATH=$ORACLE_HOME/lib:/lib:/usr/lib; export LD_LIBRARY_PATH
CLASSPATH=$ORACLE_HOME/JRE:$ORACLE_HOME/jlib:$ORACLE_HOME/rdbms/jlib; export CLASSPATH
if [ $USER = "oracle" ]; then
if [ $SHELL = "/bin/ksh" ]; then
ulimit -p 16384
ulimit -n 65536
else
ulimit -u 16384 -n 65536
fi
fi
Configurer SSH pour le « User Equivalence »
Le « User Equivalence » désigne la possibilité d'accès et d'exécution de commandes d'un noeud à l'autre, par ssh, sans demande de mot de passe. Ouvrir nue console en tant qu'utilisateur « oracle » sur chacun des noeuds.
Créer sur chacun d'eux un jeu de clé DSA (ne PAS renseigner la passphrase, sinon ssh la demandera à la connexion, ce qu'on veut justement éviter) :
$ mkdir ~/.ssh
$ chmod 700 ~/.ssh
$ /usr/bin/ssh-keygen -t dsa
Generating public/private dsa key pair.
Enter file in which to save the key (/home/oracle/.ssh/id_dsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/oracle/.ssh/id_dsa.
Your public key has been saved in /home/oracle/.ssh/id_dsa.pub.
The key fingerprint is:
af:37:ca:69:3c:a0:08:97:cb:9c:0b:b0:20:70:e3:4a oracle@rac1.localdomainCopier le contenu du fichier ~/.ssh/id_dsa.pub généré et le coller dans un fichier « ~/.ssh/authorized_keys » sur tous les noeuds. Localement d'abord :
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
$ chmod 644 ~/.ssh/authorized_keysPuis sur l'autre noeud :
$ ssh oracle@rac2 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
The authenticity of host 'ds2 (192.168.200.52)' can't be established.
RSA key fingerprint is d1:23:a7:df:c5:fc:4e:10:d2:83:60:49:25:e8:eb:11.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'ds2,192.168.200.52' (DSA) to the list of known hosts.
oracle@ds2's password:
$ ssh oracle@rac2
oracle@ds2's password:
$ chmod 644 ~/.ssh/authorized_keys
$ exitRéaliser ces opérations sur chacun des noeuds, pour « croiser » les clés.
Vérifier que chacun se connecte localement et sur l'autre serveur par ssh sans demande de mot de passe. Exemple sur rac1 :
$ hostname
rac1.localdomain
$ ssh rac1
Last login: Fri Oct 22 11:49:35 2010 from 10.1.86.201
$ exit
Connection to rac1 closed.
oacle$ ssh rac2
Last login: Fri Oct 22 12:11:04 2010 from 10.1.86.201
$ exit
Connection to rac2 closed.A partir du serveur sur lequel sera lancée l'installation de Clusterware, initialiser le « User Equivalence » (attention, cette équivalence n'est active que pour la session en cours) :
$ exec /usr/bin/ssh-agent $SHELL
$ /usr/bin/ssh-add
Identity added: /oracle/.ssh/id_dsa (/oracle/.ssh/id_dsa)Installer Clusterware
Décompresser l'archive 10201_clusterware_linux_x86_64.zip, aller dans le répertoire ainsi créé et lancer l'installateur (attention, à partir d'une session ssh, le DISPLAY doit être initialisé pour accéder au poste client ; ou, éventuellement, lancer ssh avec l'option -X (X11 forwarding).
$ unzip 10201_clusterware_linux_x86_64.zip
$ cd clusterware
$ ./runInstaller- Cliquer sur « Next »
- Accepter le répertoire « oraInventory » par défaut.
- Entrer le chemin correct pour l'ORACLE_HOME du cluster. Ici :
« /oracle/product/10.2.0/crs »- Attendre la vérification des pré-requis. Si une vérification échoue, régler le problème et cliquer sur « Retry ».
Il est possible de continuer en laissant un pré-requis mineur irrésolu, auquel cas un écran d'avertissement s'affiche.
- L'écran suivant liste noeud correspondant au système local. Cliquer sur « Add » pour ajouter le second noeud.
- Entrer les information du second noeud.
- Une fois les deux noeuds définis, cliquer sur « Next ».
- Définir l'usage des interfaces réseau : ici, on éditera « eth0 » (qui, contrairement à l'écran ci-joint, est pour notre exemple sur le réseau 10.1.86.0) pour lui donner le type « Public ».
- Sélectionner eth0 et cliquer sur « Edit ».
- Eth1 restera sur 192.168.1.0 en « Private ».
- Pour l'emplacement du registre OCR, sélectionner « External redundancy », si la partition prévue est sécurisée par du RAID matériel (sinon, prévoir 2 ou 3 partitions, et demander à Oracle de gérer la redondance en sélectionnant « Normal redundancy »)
- Idem pour le « Voting disk ».
- Accepter le résumé si tout est correct,
et attendre la fin de l'installation.
A la fin de l'installation, lancer sur les 2 noeuds les scripts indiqués, en tant que « root ».
Le script orainstRoot.sh doit afficher ce type de messages :
cd /u01/app/oracle/oraInventory
./orainstRoot.sh
Changing permissions of /u01/app/oracle/oraInventory to 770.
Changing groupname of /u01/app/oracle/oraInventory to oinstall.
The execution of the script is completeSur le premier noeud (celui sur lequel a été lancé runIstaller), root.sh initialise l'OCR et le Voting Disk (cf plus bas si des erreurs apparaissent au lancement de root.sh) :
cd /u01/crs/oracle/product/10.2.0/crs
./root.sh
WARNING: directory '/u01/crs/oracle/product/10.2.0' is not owned by root
WARNING: directory '/u01/crs/oracle/product' is not owned by root
WARNING: directory '/u01/crs/oracle' is not owned by root
WARNING: directory '/u01/crs' is not owned by root
WARNING: directory '/u01' is not owned by root
Checking to see if Oracle CRS stack is already configured
/etc/oracle does not exist. Creating it now.
Setting the permissions on OCR backup directory
Setting up NS directories
Oracle Cluster Registry configuration upgraded successfully
WARNING: directory '/u01/crs/oracle/product/10.2.0' is not owned by root
WARNING: directory '/u01/crs/oracle/product' is not owned by root
WARNING: directory '/u01/crs/oracle' is not owned by root
WARNING: directory '/u01/crs' is not owned by root
WARNING: directory '/u01' is not owned by root
assigning default hostname rac1 for node 1.
assigning default hostname rac2 for node 2.
Successfully accumulated necessary OCR keys.
Using ports: CSS=49895 CRS=49896 EVMC=49898 and EVMR=49897.
node <nodenumber>: <nodename> <private interconnect name> <hostname>
node 1: rac1 rac1-priv rac1
node 2: rac2 rac2-priv rac2
Creating OCR keys for user 'root', privgrp 'root'..
Operation successful.
Now formatting voting device: /dev/raw/raw2
Format of 1 voting devices complete.
Startup will be queued to init within 90 seconds.
Adding daemons to inittab
Expecting the CRS daemons to be up within 600 seconds.
CSS is active on these nodes.
rac1
CSS is inactive on these nodes.
rac2
Local node checking complete.
Run root.sh on remaining nodes to start CRS daemons.Les « WARNINGS » sur les propriétaires des répertoires peuvent être ignorés.
Sur l'autre noeuds, certaines opérations sont omises car déjà réalisées sur le noeud 1 :
cd /u01/crs/oracle/product/10.2.0/crs
./root.sh
WARNING: directory '/u01/crs/oracle/product/10.2.0' is not owned by root
WARNING: directory '/u01/crs/oracle/product' is not owned by root
WARNING: directory '/u01/crs/oracle' is not owned by root
WARNING: directory '/u01/crs' is not owned by root
WARNING: directory '/u01' is not owned by root
Checking to see if Oracle CRS stack is already configured
/etc/oracle does not exist. Creating it now.
Setting the permissions on OCR backup directory
Setting up NS directories
Oracle Cluster Registry configuration upgraded successfully
WARNING: directory '/u01/crs/oracle/product/10.2.0' is not owned by root
WARNING: directory '/u01/crs/oracle/product' is not owned by root
WARNING: directory '/u01/crs/oracle' is not owned by root
WARNING: directory '/u01/crs' is not owned by root
WARNING: directory '/u01' is not owned by root
clscfg: EXISTING configuration version 3 detected.
clscfg: version 3 is 10G Release 2.
assigning default hostname rac1 for node 1.
assigning default hostname rac2 for node 2.
Successfully accumulated necessary OCR keys.
Using ports: CSS=49895 CRS=49896 EVMC=49898 and EVMR=49897.
node <nodenumber>: <nodename> <private interconnect name> <hostname>
node 1: rac1 rac1-priv rac1
node 2: rac2 rac2-priv rac2
clscfg: Arguments check out successfully.
NO KEYS WERE WRITTEN. Supply -force parameter to override.
-force is destructive and will destroy any previous cluster
configuration.
Oracle Cluster Registry for cluster has already been initialized
Startup will be queued to init within 90 seconds.
Adding daemons to inittab
Expecting the CRS daemons to be up within 600 seconds.
CSS is active on these nodes.
rac1
rac2
CSS is active on all nodes.
Waiting for the Oracle CRSD and EVMD to start
Waiting for the Oracle CRSD and EVMD to start
Waiting for the Oracle CRSD and EVMD to start
Waiting for the Oracle CRSD and EVMD to start
Waiting for the Oracle CRSD and EVMD to start
Waiting for the Oracle CRSD and EVMD to start
Waiting for the Oracle CRSD and EVMD to start
Oracle CRS stack installed and running under init(1M)
Running vipca(silent) for configuring nodeapps
The given interface(s), "eth0" is not public. Public interfaces should be used to configure virtual IPs.En cas d'erreurs, sans sortir de runInstaller et de l'écran « Execute configuration scripts » (runInstaller sous Xwindow fonctionne en tâche de fond et ne bloque pas la console ssh à partir de laquelle il est lancé : appuyer sur « Entrée » pour retrouver le prompt), appliquer les corrections suivantes :
- Erreur 1 :
PROT-1: Failed to initialize ocrconfig
Failed to upgrade Oracle Cluster Registry configurationIl faut appliquer un patch spécifique aux systèmes 64 bits. Le patch 4679769 est téléchargeable sur le site d'Oracle Metalink. Il ne contient qu'un exécutable (clsfmt.bin) à placer dans le répertoire $ORACLE_HOME/bin (sauvegarder l'ancien clsfmt.bin avant de l'écraser).
- Erreur 2 :
/u01/app/oracle/product/crs/jdk/jre//bin/java: error while loading shared libraries: libpthread.so.0: cannot open shared object file: No such file or directoryil faut éditer deux fichiers :
dans $ORACLE_HOME/vipca, commenter les lignes suivantes (aux alentours de la ligne 120) :
if [ "$arch" = "i686" -o "$arch" = "ia64" ]
then
LD_ASSUME_KERNEL=2.4.19
export LD_ASSUME_KERNEL
fidans $ORACLE_HOME/srvctl, chercher et commenter également ces lignes :
#Remove this workaround when the bug 3937317 is fixed
LD_ASSUME_KERNEL=2.4.19
export LD_ASSUME_KERNEL- Erreur 3 : La dernière étape du script root.sh (lancement de « vipca » en mode silencieux) échoue la plupart du temps parce que l'adresse VIP est souvent dans une plage d'adresses privées (192.168.1) :
Error 0(Native: listNetInterfaces:[3])
[Error 0(Native: listNetInterfaces:[3])]Il faut alors le relancer manuellement :
cd /u01/crs/oracle/product/10.2.0/crs/bin
./vipca-
- Cliquer sur « Next » sur l'écran d'accueil.
- Sélectionner eth0 et cliquer sur « Next »
- Entrer les adresse IP virtuelles de chaque noeud.
- Accepter le résumé en cliquant sur « Finish ».
Attendre la fin de l'installation pour valider le résultat en cliquant sur « Exit ».
A ce moment, on retourne sur l'écran « Execute Configuration scripts », qu'on peut valider.
De la même manière, attendre la fin de l'installation pour valider en cliquent sur « Exit ».
Installer Database Server et créer l'instance ASM
IMPORTANT : si Oracle est déjà installé sur un ou plusieurs des serveurs constituant le cluster (exemple : Oracle 10g 10.2.0.1 est installé en « single » sur un serveur, on ne peut pas le mettre à jour pour des raisons de compatibilité avec une application. On installe Oracle 10g RAC 10.2.0.4 dans un ORACLE_HOME séparé), s'assurer que l'utilisateur qui lance l'installation de Database Server en RAC a les droits d'écriture sur le répertoire parent de son ORACLE_HOME.
Exemple : Oracle 10.2.0.1 est installé dans /oracle/product/10.2.0/db_1, on veut installer Oracle 10.2.0.4 en RAC dans /oracle/product/10.2.0/db_2. L'utilisateur doit avoir les droits d'écriture sur /oracle/product/10.2.0 pour créer son arborescence et copier ses fichiers.
S'assurer que ce même utilisateur a les droits d'écriture sur /etc/oratab
L'instance ASM est nécessaire pour la gestion par Oracle des volumes ASM qui contiendront les données des bases utilisateurs. Elle doit donc être créée avant toute autre base. Elle n'est constituée que d'une instance en mémoire, elle n'a pas de fichier de données sur disque, à part son SPFILE.
Comme pour Clusterware, décompresser l'archive et lancer runInstaller.
oracle$ unzip 10201_database_linux_x86_64.zip
oracle$ cd database
oracle$ ./runInstaller- Cliquer sur « Next » sur l'écran d'accueil
- Sélectionner « Enterprise Edition » et cliquer sur « Next »
- Indiquer le répertoire d'installation (ORACLE_HOME). Si une autre version d'Oracle est déjà installée et qu'il ne faut pas l'écraser, changer le nom et le répertoire (pour « db_2 » par exemple)
- Sélectionner « Cluster Installation » et cocher les 2 noeuds du cluster
- Vérifier les pré-requis, corriger les problèmes éventuels
- Créer l'instance ASM, donner le mot de passe SYS de l'instance
- Si la redondance doit être gérée par Oracle, sélectionner « High » (RAID5) ou « Normal » (RAID1) et indiquer les partitions à intégrer au RAID logiciel.
- Si la sécurité est assurée par le matériel, sélectionner « External » et indiquer une ou plusieurs partitions (dont les tailles s'ajouteront, dans ce cas)
- Valider le résumé en cliquant sur « Install ».
Attendre que l'installation se termine et la fin des assistants de configuration.
Exécuter le script « root.sh » comme indiqué sur tous les noeuds du cluster
Valider la fin de l'installation.
Oracle Database Server est désormais installé, et l'instance ASM créée. Les bases utilisateurs peuvent désormais être créées avec « dbca » (DataBase Configuration Assistant), en indiquant si on souhaite intégrer cette base au cluster, ou l'installer sulement en « single » sur un des noeuds.
Lors de l'installation, on indiquera le groupe ASM « DATA » comme destination de la base de données.
Mémento de commandes cluster RAC
Contrôler le cluster
Contrôler l’état des ressources du cluster
Pour cela on utilise la commande crs_stat du clusterWare :
(l'option -t sert à obtenir une sortie tabulée, l'option -v permet d'obtenir quelque chose de plus verbeux)
$ $CRS_HOME/bin/crs_stat -t -v Name Type R/RA F/FT Target State Host ---------------------------------------------------------------------- ora....11.inst application 0/5 0/0 ONLINE ONLINE NODE1 ora....12.inst application 0/5 0/0 ONLINE ONLINE NODE2 ora....db1.srv application 0/0 0/0 ONLINE ONLINE NODE1 ora....db2.srv application 0/0 0/0 ONLINE ONLINE NODE2 ora....bsrv.cs application 0/0 0/1 ONLINE ONLINE NODE2 ora.clustdb.db application 0/0 0/1 ONLINE ONLINE NODE1 ora....SM1.asm application 0/5 0/0 ONLINE ONLINE NODE1 ora....E1.lsnr application 0/5 0/0 ONLINE ONLINE NODE1 ora....DE1.gsd application 0/5 0/0 ONLINE ONLINE NODE1 ora....DE1.ons application 1/10 0/0 ONLINE ONLINE NODE1 ora....DE1.vip application 0/0 0/0 ONLINE ONLINE NODE1 ora....SM2.asm application 0/5 0/0 ONLINE ONLINE NODE2 ora....E2.lsnr application 0/5 0/0 ONLINE ONLINE NODE2 ora....DE2.gsd application 0/5 0/0 ONLINE ONLINE NODE2 ora....DE2.ons application 3/10 0/0 ONLINE ONLINE NODE2 ora....DE2.vip application 0/0 0/0 ONLINE ONLINE NODE2 Si on veut obtenir le nom complet des ressources, il faut utiliser la commande crs_stat sans option.
Note : Cette commande reflète l’état des ressources dans le OCR.
Arrêt/démarrage d’une instance dans le cluster
pour arréter l'instance clustdb1 de la base de cluster clustdb :
$ $ORACLE_HOME/bin/srvctl stop instance -i clustdb1 -d clustdb pour démarrer l'instance clustdb2 de la base de cluster clustdb
$ $ORACLE_HOME/bin/srvctl start instance -i clustdb2 -d clustdbArrêt/démarrage d’une ressource ASM (Automatic Storage Management)
pour arréter la ressource ASM sur le noeud NODE1
$ $ORACLE_HOME/bin/srvctl stop asm -n NODE1pour démarrer la ressource ASM sur le noeud NODE2
$ $ORACLE_HOME/bin/srvctl start asm -n NODE2Arrêt/démarrage d’une resource listener
pour arréter la ressource listener sur le noeud NODE2
$ $ORACLE_HOME/bin/srvctl stop listener -n NODE2pour démarrer la ressource listener sur le noeud NODE1
$ $ORACLE_HOME/bin/srvctl start listener -n NODE1Arrêt/démarrage de toutes les ressources d’un même noeud
pour arréter les ressources du noeud NODE2
$ $ORACLE_HOME/bin/srvctl stop nodeapps -n NODE2pour démarrer les ressources du noeud NODE1
$ $ORACLE_HOME/bin/srvctl start nodeapps -n NODE1Arrêt/démarrage d’une ressource particulière
pour arréter la ressource "ora.NODE1.ons"
$ $CRS_HOME/bin/crs_start ora.NODE1.ons
Attempting to start `ora.NODE1.ons` on member `NODE1`
Start of `ora.NODE1.ons` on member `NODE1` succeeded.pour démarrer la ressource "ora.NODE1.ons"
$ $CRS_HOME/bin/crs_stop ora.NODE1.ons
Attempting to stop `ora.NODE1.ons` on member `NODE1`
Stop of `ora.NODE1.ons` on member `NODE1` succeeded. Contrôler le clusterWare CRS (Cluster Ready Services)
Contrôler le statut des processus CRS
$ $CRS_HOME/bin/crsctl check crs
CSS appears healthy
CRS appears healthy
EVM appears healthyArréter et redémarrer le CRS
Attention, ces processus appartenant à root, ils doivent être réaliser par cet utilisateur. De plus, ces commandes sont asynchrones, veillez donc à contrôler l’état du CRS après avoir taper ces commandes.
Pour arréter le service :
$CRS_HOME/bin/crsctl stop crsPour démarrer le service :
$CRS_HOME/bin/crsctl start crsObtenir la localisation du ou des disques votant (ou voting disks)
Ceci s’effectue avec la commande suivante :
$ $CRS_HOME/bin/crsctl query css votedisk
0. 0 /dev/rdsk/emcpower0g
located 1 votedisk(s).Contrôle de l’OCR
L’OCR (Oracle Cluster Registry) contient, comme son nom l’indique, la défition du cluster : les noeuds, les bases, les instances, les services etc.
Il peut être décliné sous deux formes :
- un simple fichier sur un système de fichiers en cluster (car il doit être accessible des deux noeuds)
- une partition brute partagée (Shared Raw partition). De plus, ces fichiers/partitions peuvent être multiplexées sur différents axes. (Si il est unique, la redondance est laissée à un système tiers : RAID, mirroring de baies, SAN etc.
Il est donc important, dans la gestion de son cluster, de connaître les informations de l’OCR (localisation, taille, redondance etc.), mais aussi de savoir le sécuriser en le sauvegardant, et enfin de savoir le restaurer en cas de perte du volume/fichier.
Obtenir les infos de l’OCR
Les infos de l’OCR s’obtiennent avec la commande ocrcheck.
$ $CRS_HOME/bin/ocrcheck
Status of Oracle Cluster Registry is as follows :
Version : 2 <----- Version du registre
Total space (kbytes) : 51200 <----- Espace total alloué au registre
Used space (kbytes) : 6220 <----- Taille du registre
Available space (kbytes) : 44980 <----- Espace disponible
ID : 507221704
Device/File Name : /dev/rdsk/emcpower1g <----- Emplacement
du registre
Device/File integrity check succeeded
^----- Vérification de
l'intégrité du périphérique
Device/File not configured
^----- Définition de la deuxième
partition (si multipléxé)
Cluster registry integrity check succeededExporter et importer l’OCR
L’export et l’import de l’OCR se fait par la commande ocrconfig. Dans la mesure où l’OCR (qu’il soit fichier ou partition brute) est détenu par root, mais qu’il reste accessible en lecture aux utilisateur du groupe dba. Il est conseillé de réaliser l’export en tant qu’utilisateur oracle (par exemple). L’import doit, quant à lui, être réalisé par le root.
Le but de l’opération est donc de garder une copie de l’OCR (dans un format texte certes, mais peu lisible ;) ). Cette copie peut-être réalisé en cas de perte de la partition, ou de corruption des données du registre.
- Export de l’OCR
$ $CRS_HOME/bin/ocrconfig -export export_File.dmp -s onlinel'option "-s online" permet d'effectuer cet export en ligne sans arréter le CRS.
- Import de l’OCR
Eventuellement restaurer/recrer la partition, et ou le fichier.
$ $CRS_HOME/bin/ocrconfig --import export_File.dmp- Sauvegarder à froid l’OCR
La sauvegarde à froid de l’OCR, se réalise simplement :
-
- par une copie de fichier, si l’OCR est matérialisé dans un ou plusieurs fichiers
- par un ordre unix "dd", dans le cas d’une partition partagées. Pour l’import par dd, il suffit d’inverser l’input file (if) et l’output file (of) dans la commande dd :
pour exporter :
dd if=/dev/rdsk/emcpower1g of=/HOME/ocr/backup/ocr_010507.bkp bs=1024 count=51200pour importer :
dd if=/HOME/ocr/backup/ocr_010507.bkp of=/dev/rdsk/emcpower1g bs=1024 count=51200impdp dblink - Importer des données sans export préalable
Sur la base cible, créer un DBLINK vers la base source :
sqlplus / as sysdba
SQL> create database link LINK_TO_DB
connect to system identified by Passw0rd
using 'TNS_TO_DB';
SQL> exit;Une fois le lien de base de données créé, lancer l’import datapump. Celui-ci créera tous les objets, y compris le ou les utilisateur(s) :
$ impdp "/ as sysdba" schemas=scott remap_schema=scott:myscott nologfile=y network_link=LINK_TO_DB
ou
$ impdp "/ as sysdba" schemas=scott,tiger,hr nologfile=y network_link=LINK_TO_DB
Import de schémas utilisateurs
NOTE : penser à redémarrer la base avant l'import pour couper d'éventuelles session et/ou requêtes qui bloqueraient les tables
NOTE 2 : penser à couper le LISTENER pendant l'import
Deux solutions :
1. Supprimer (DROP USER...CASCADE) les schémas à recréer dans la base cible, et charger les schémas qui seront recréés :
impdp system/password@ORCL DIRECTORY=DIR DUMPFILE=exp_full.dmp SCHEMAS=scott,hr2. Ecraser les tables des schémas existants :
impdp system/password@ORCL DIRECTORY=DIR DUMPFILE=exp_full.dmp SCHEMAS=scott,hr TABLE_EXISTS_ACTION=replaceNOTE : cette méthode peut générer des erreurs, par exemple si un index est déjà UNUSABLE sur la base, ou des erreurs de clés dupliquées qui n'ont pas lieu d'être. Dans ce cas, revenir à la méthode 1.
Si les schémas doivent être réimportés sous un autre nom :
impdp system/password@ORCL DIRECTORY=DIR DUMPFILE=exp_full.dmp SCHEMAS=scott REMAP_SCHEMA=SCOTT:OTHER_SCHEMALISTENER : enregistrement automatique des bases
Si le listener.ora ne contient que le minimum, ex :
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = hostname.domain)(PORT = 1521))
)
)
les bases s'enregistrent automatiquement (le LISTENER sur le port 1521 est essayé par défaut au démarrage de la base).
S'il y a plusieurs listener (ex : un second sur le port 1522), il faut dire aux bases lequel doit écouter pour chacune d'elles.
C'est possible par le paramètre LOCAL_LISTENER.
Deux possibilités
- remplir ce paramètre avec un chemin réseau complet :
LOCAL_LISTENER = (ADDRESS = (PROTOCOL=TCP)(HOST=hostname)(PORT=1522)) - ou avec un alias du listener (ajouté dans le tnsnames.ora du serveur, comme pour une base). Exemple de tnsnames :
LISTENER_1522 = (ADDRESS = (PROTOCOL = TCP)(HOST = hostname)(PORT = 1522))
on initialisera ensuite
LOCAL_LISTENER = LISTENER_1522
Temps d'enregistrement
le processus PMON met par défaut environ 60 secondes pour enregistrer une base qui aurait démarré après son LISTENER. Si on veut forcer l'enregistrement :
SQL> alter system register;Migration par transport tablespace
On veut migrer une base 11.2.0.4 MYDB sur un serveur_source vers une base 19c sur un nouveau serveur serveur_destination. Mais la base est volumineuse et un export/import n'est pas envisageable en terme de temps de migration. On transporte donc les tablespaces utilisateurs (sans SYSTEM, SYSAUX, TEMP et UNDO).
Le nom de la base et le chemin des fichiers est le même que sur le serveur source. S'il faut changer les chemins ou renommer les fichiers, se reporter à la procédure pour déplacer les fichiers d'une base.
Sur la base SOURCE 11g
Avant de lancer la migration
- Vérifier s'il n'y a pas d'incompatibilité au TRANSPORT_TABLESPACE
EXECUTE DBMS_TTS.TRANSPORT_SET_CHECK('TBLSP_1,TBLSP_2,TBLSP_3',TRUE);
SELECT * FROM TRANSPORT_SET_VIOLATIONS;
aucune ligne selectionnee- Lister les fichiers des tablespaces à transporter (liste nécessaire pour le futur import)
SELECT file_name FROM dba_data_files;- Faire un export des metadonnées uniquement :
expdp system/'system_password' DUMPFILE=exp_TTS_MYDB.dmp DIRECTORY=DUMP FULL=Y CONTENT=METADATA_ONLY- Extraire les DDLs dans un fichier SQL avec impdp:
impdp system/'system_password' DUMPFILE=exp_TTS_MYDB.dmp DIRECTORY=DUMP SQLFILE=MYDB.sqlDans ce fichier SQL, extraire les ordres de création pour :
- recréer le tablespace TEMP avec le bon nom (si spécifique)
- recréer les utilisateurs non-systèmes avec ses GRANT
- recréer les DIRECTORY
Au moment de la migration
Stopper le LISTENER, redémarrer la base pour être sûr qu'il n'y a plus de sessions utilisateurs
lsnrctl stop
sqlplus / as sysdba
SQL> shutdown immediate;
SQL> startupPasser les tablespaces utilisateurs en read only
alter tablespace TBLSP_1 read only;
alter tablespace TBLSP_2 read only;
alter tablespace TBLSP_3 read only;Exporter les métadonnées spécifiquement liées aux tablespaces transportés :
expdp system/'system_passwd' DUMPFILE=exp_TTS_MYDB.dmp DIRECTORY=DUMP TRANSPORT_TABLESPACES=TBLSP_1,TBLSP_2,TBLSP_3 LOGFILE=exp_TTS_MYDB.logCopier les fichiers des tablespaces utilisateurs vers le nouveau serveur en 19c, ainsi que le dump des metadonnées des tablespaces :
scp /u01/mydb/tblsp_* serveur_dest:/u01/mydb
scp /export/expdp_TTS_MYDB.exp serveur_dest:/exportA ce stade la base 11g sur serveur_source peut être remise en read write, mais ce n'est pas forcément souhaitable, si on compte passer la production sur la base 19c :
sqlplus / as sysdba
alter tablespace TBLSP_1 read write;
alter tablespace TBLSP_2 read write;
alter tablespace TBLSP_3 read write;
exit
lsnrctl startSur la base DESTINATION 19c
Important : Créer la base en mode personnalisé, avec compatible=11.2.0 et vérifier les paramètres NLS de la base source pour bien remettre les mêmes. Pour l'instant, seul le tablespace USERS par défaut est laissé sur la base.
Recréer les utilisateurs Oracle (qui auront le tablespace USERS par défaut, puisque les autres tablespaces ne sont pas encore rattachés) par rapport au DDL extrait plus haut.
CREATE USER "APPLIUSER" IDENTIFIED BY VALUES '622F2895A4A8F54E' TEMPORARY TABLESPACE "TEMP";
ALTER USER "APPLIUSER" DEFAULT ROLE ALL;Et les DIRECTORIES :
CREATE DIRECTORY DUMP AS '/export';Importer les metadonnées des tablespaces transportés. Contrairement à l'export sur la base source, ici on liste tous les fichiers des tablespaces transportés, pas seulement le nom des tablesapces :
impdp system/'system_password!' DUMPFILE=exp_TTS_MYDB.dmp DIRECTORY=DUMP TRANSPORT_DATAFILES=/u01/mydb/tblsp_1_01.dbf TRANSPORT_DATAFILES=/u01/mydb/tblsp_1_02.dbf TRANSPORT_DATAFILES=/u01/mydb/tblsp_2_01.dbf TRANSPORT_DATAFILES=/u01/mydb/tblsp_2_01.dbf LOGFILE=imp_TTS_MYDB.logRepasser les tablespace en read write :
alter tablespace TBLSP_1 read write;
alter tablespace TBLSP_2 read write;
alter tablespace TBLSP_3 read write;Modifier les utilisateurs pour leur attribuer le bon tablespace par défaut :
ALTER USER "APPLIUSER" DEFAULT TABLESPACE "TBLSP_1";Si le tablespace USERS n'a plus d'utilité, le supprimer :
drop tablespace USERS including contents and datafiles;Repasser le paramètre compatible en version 19 et valider la configuration de la base par un redémarrage :
alter system set compatible='19.0.0' scope=spfile;
SHUTDOWN IMMEDIATE;
STARTUP; Mode ARCHIVELOG
Activation du mode ARCHIVELOG :
Vérifier ou forcer le chemin et le format des archive logs :
$ sqlplus / as sysdba
SQL> show parameter log_archive_dest
SQL> alter system set log_archive_dest_1 = 'LOCATION=/u01/data/MABASE/archives';
SQL> show parameter log_archive_format
SQL> alter system set log_archive_format = '%t_%s_%r.dbf';Activer l'ARCHIVELOG :
SQL> shutdown immediate;
SQL> startup mount;
SQL> ALTER DATABASE ARCHIVELOG;
SQL> ALTER DATABASE OPEN;Vérification :
SQL> archive log list;
SQL> alter system switch logfile;Vérifier la création d'une archive dans le répertoire
Désactivation du mode ARCHIVELOG :
même procédure avec NOARCHIVELOG:
SQL> shutdown immediate;
SQL> startup mount;
SQL> ALTER DATABASE NOARCHIVELOG;
SQL> ALTER DATABASE OPEN;
SQL> archive log list;NLS LANG et nls_*_parameters et SQLPLUS en UTF8
Oracle 10 server : NLS_LANG, nls_*_parameters
Il y a 3 niveaux de NLS :
- database (nls_database_parameters -> vue statique) : initialisés à la création de la base, immuable
- instance (v$nls_parameters -> vue dynamique ou nls_instance_parameters -> vue statique) : initialisés par spfile, paramètres non dynamiques
- session (nls_session_parameters -> vue statique) : changés par alter session
Session si non paramétré prend la valeur d'Instance qui si non paramétré prend la valeur de Database.
MAIS il y a un autre paramètre qui peut tout changer : NLS_LANG, paramètre d'environnement OS. Or sur Windows il est paramétré dans les registres.
Exemples :
- NLS_LANG=AMERICAN_AMERICA.WE8ISO8859.
Une base crée en AMERICAN_AMERICA prendra cette valeur par défaut. Si on change le spfile, l'instance sera bien en FRENCH_FRANCE, MAIS les sessions utilisateurs resteront en AMERICAN_AMERICA à cause du NLS_LANG.
Par contre une base créée en FRENCH_FRANCE reportera bien ces paramètres sur instance et sessions.
- NLS_LANG=FRENCH_FRANCE.WE8ISO8859.
La base créée en AMERICAN_AMERICA prend FRENCH_FRANCE au redémarrage. Si on a modifié le spfile, les sessions sont aussi en FRENCH_FRANCE.
SQLPLUS en UTF8
Pour insérer des données UTF8 dans une base, il ne suffit pas que celle-ci ait été créée en UTF8 : il faut que sqlplus sur le client qui fait les insertions soit paramétré en UTF8, ce qui n'est pas la valeur par défaut.
Linux
sur une machine linux, on peut soit initialiser l'environnement, soit lancer sqlplus avec un environnement personnalisé :
export NLS_LANG=FRENCH_FRANCE.UTF8
export ORACLE_SID=orcl
sqlplusou
export ORACLE_SID=orcl
NLS_LANG=FRENCH_FRANCE.UTF8 sqlplusPutty
Note pour putty : si on se connecte à la machine linux par putty, il faut d'abord modifier la configuration de votre session putty (Dans Window → Translation) pour choisir le jeu de caractères UTF-8.
Windows
Sur windows, ouvrir une fenêtre DOS, et intialiser l'environnement avant de lancer sqlplus :
C:\> set NLS_LANG=FRENCH_FRANCE.UTF8
C:\> set ORACLE_SID=orcl
C:\> sqlplusOracle 11gR2 sur RedHat 7 64 bits
Installation RedHat 7
1. Télécharger la dernière image ISO RedHat sur https://access.redhat.com
2. Créer une VM
- ressources : 16G RAM, 300G disque format dynamique
- Faire pointer le lecteur cd vers l'ISO RedHat
3. Activer (booter) la VM
4. IMPORTANT : L'installateur graphique de RedHat ne s'affiche pas correctement par défaut dans la console VMWare. Au lancement :
- Aller dans « Troubleshooting » / « install in basic graphic mode »
- Touche TABULATION
- remplacer "xdriver=vesa" par "vga=794", valider.
Note : on a pas ce problème sur une VM KVM.
5. Sur l'écran « Installation summary », choisir la langue et le clavier
6. Paramétrer le réseau dans « Network & hostname » (sélectionner la carte et cliquer sur « Configure »)
7. Paramétrer les partitions dans « Installation destination »
8. Sélectionner le disque de destination, demander la création des partitions automatiquement, puis supprimer /home (l'assistant crée une partition /home distincte sur le reste du disque. On veut garder cette place pour un "/u01" qui contiendra Oracle)
9. Revenir sur l'écran d’accueil et cliquer sur « Begin installation »
10. Pendant l'installation, créer le mot de passe root, ne pas créer d'autre utilisateur.
Une fois le système installé et la VM redémarrée, s'y connecter en SSH.
11. Vérifier que la VM a accès à internet
12. Enregistrer le système auprèsde Redhat :
subscription-manager register
Le système a été enregistré avec l'ID : xxxxxx-xxxx-xxxx-xxxx-xxxxxxxxx13. Lister les souscriptions disponibles et noter le numéro « ID du pool »,
subscription-manager list --available 14. Souscrire à ce pool (ID ci-dessus sans les tirets)
subscription-manager subscribe --pool=xxxxxxxxxxxxxxxxxxxxxxxxxx 15. Vérification :
subscription-manager list --consumed16. Vérifier les dépôts activés
yum repolist allle dépôt « rhel-7-server-rpms/7Server/x86_64 » doit être actif 17. Mettre le système à jour
yum updatePréparation de l'installation d'Oracle 11gR2 par YUM
Selon http://www.snapdba.com/2014/01/oracle-database-11gr2-11-2-0-4-installation-on-oracle-linux-6-4/ et http://www.snapdba.com/2013/03/oracle-linux-6-4-installation-64-bit : en activant les dépôt d'Oracle linux (ou en installant directement Oracle linux), les pré-requis peuvent être automatisés par
yum install oracle-rdbms-server-11gR2-preinstallA valider ! Et voir ce que ça automatise par rapport au chapitre ci-dessous.
Installation d'Oracle 11gR2 manuellement
1. Télécharger les fichiers sur https://support.oracle.com (au minimum : fichiers 1 et 2 (database), 4 (client), et 7 (uninstall))
2. Installer les pré-requis (le dépôt additionnel « server-optional-rpms est nécessaire pour le paquet compat-libstdc++-33)
yum install yum-utils xauth unzip psmisc
yum-config-manager --enable rhel-7-server-optional-rpms
yum install ksh binutils glibc compat-libstdc++-33 compat-libcap1 glibc-common glibc-devel glibc-headers elfutils-libelf elfutils-libelf-devel elfutils gcc gcc-c++ ksh libaio libaio-devel libgcc libstdc++-devel make libXi libXtst numactl-devel sysstat mksh unixODBC unixODBC-devel 3. Formater et monter une partition LVM /u01 à partir de l'espace libre restant sur le disque.
4. Initialiser l'arborescence Oracle
mkdir -p /u01/app/oracle/product/11.2.0/dbhome_1 5. Créer groupes et utilisateur
groupadd -g 502 oinstall
groupadd -g 503 dba
groupadd -g 504 oper
groupadd -g 505 asmadmin # UTILE ??
useradd -u 502 -g oinstall -G dba,oper -d /u01 -s /bin/bash oracle11
passwd oracle11 6. Changer les droits de /u01
chown -R oracle11:oinstall /u01
chmod -R 775 /u017. Adapter les paramètres système pour Oracle
vi /etc/sysctl.d/99-sysctl.confajouter :
#### Oracle 11g Kernel Parameters ####
fs.suid_dumpable = 1
fs.aio-max-nr = 1048576
fs.file-max = 6815744
kernel.shmall = 2097152
kernel.shmmax = 4294967296
kernel.shmmni = 4096
# semaphores: semmsl, semmns, semopm, semmni
kernel.sem = 250 32000 100 128
net.ipv4.ip_local_port_range = 9000 65500
net.core.rmem_default=4194304
net.core.rmem_max=4194304
net.core.wmem_default=262144
net.core.wmem_max=1048586
vi /etc/security/limits.confajouter :
#### oracle User Settings 4 Oracle 11g ####
oracle11 soft nproc 2047
oracle11 hard nproc 16384
oracle11 soft nofile 4096
oracle11 hard nofile 65536
oracle11 soft stack 10240
oracle11 hard stack 32768 appliquer les paramètres :
/sbin/sysctl -p 8. Désactiver SELINUX et le firewall local
systemctl stop firewalld
systemctl disable firewalld
vi /etc/selinux/configmodifier :
SELINUX=disabled 9. Se connecter sous l'utilisateur Oracle (attention aux espaces autour du « - »)
su - oracle11
vi .bashrcajouter :
# Oracle Settings
TMP=/tmp; export TMP
TMPDIR=$TMP; export TMPDIR
ORACLE_BASE=/u01/app/oracle; export ORACLE_BASE
ORACLE_HOME=$ORACLE_BASE/product/11.2.0/dbhome_1; export ORACLE_HOME
PATH=$ORACLE_HOME/bin:$PATH; export PATH
LD_LIBRARY_PATH=$ORACLE_HOME/lib:/lib:/usr/lib; export LD_LIBRARY_PATH
CLASSPATH=$ORACLE_HOME/jlib:$ORACLE_HOME/rdbms/jlib; export CLASSPATH9.1. Sur RH7 et bash, c'est .bash_profile qui est lancé en interactif. Créer .bash_profile :
vi .bash_profile# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/.local/bin:$HOME/bin
export PATHNOTE : Sur linux, en interactif (connexion à une console ou ssh), c'est .bash_profile qui est exécuté. En non-interactif (cron, su -c, etc.) c'est .bashrc qui est exécuté.
IMPORTANT : charger ces configurations avant de lancer l'installation !
source .bash_profile10. dézipper les archives oracle (par exemple dans /u01/install), donner les droits à oracle11
chown -R oracle11.oinstall /u01/install/database 11. Lancer l'installation
cd /u01/install/database
./runInstallerNOTE : l'installation est graphique. Ne pas oublier « xhost + » et « ssh -X » si client linux, ou Xming si client Windows.
Répondre Y si l'avertissement suivant s'affiche :
Vérification de l'écran : doit être configuré pour afficher au moins 256 couleurs
>>> Impossible d'exécuter la vérification automatique des couleurs d'affichage à l'aide de la commande /usr/bin/xdpyinfo. Vérifiez que la variable DISPLAY est définie. Echec <<<<
Echec de la vérification de certaines exigences. Vous devez répondre à ces exigences pour pouvoir poursuivre l'installation, Voulez-vous poursuivre ? (o/n) [n]12. Passer les différents écrans graphiques avec le bouton « suivant » :
- ne pas donner d'adresse électronique, décocher "recevoir les mises à jour..." > suivant (valider l'avertissement)
- ignorer les mises à jour > suivant (valider "ne pas être averti....")
- installer le logiciel uniquement > suivant (les bases de données seront créées individuellement plus tard)
- bases mono-instance (« single instance ») > suivant
- langues anglais+français > suivant
- Standard Edition > suivant
- vérifier les chemins ORACLE_BASE et ORACLE_HOME > suivant
- vérifier chemin oraInventory (créé automatiquement) et groupe > suivant
- vérifier groupes dba,oper > suivant
13. A la validation, le message indiquant un swap trop petite (< RAM) peut être ignoré; de même le message indiquant « pdksh » manquant peut être ignoré aussi (le package « ksh » le remplace).
S'il n'y a que ces 2 avertissements, cocher "ignorer tout" et valider.
NOTE RedHat7 : en cas d'erreur
"Erreur lors de l'appel de la cible 'agent nmhs' du fichier Make"- laisser l'installateur en attente
- aller en console dans le répertoire /u01/app/oracle/product/11.2.0.4/sysman/lib
- éditer ins_emagent.mk avec vi
- chercher MK_EMAGENT_NMECTL, remplacer la ligne :
$(MK_EMAGENT_NMECTL)par
$(MK_EMAGENT_NMECTL) -lnnz11- sauver, revenir à l'installateur et cliquer « réessayer »
14. A la fin de l'installation, exécuter en "root" les 2 scripts indiqués
Installation du patch 11.2.0.4.1
1. Le patch « DATABASE_PATCH_SET_11.2.0.4.1 » est disponible sur support.oracle.com sous le nom « p17478514_112040_Linux-x86-64.zip ».
2.Télécharger aussi la dernière version d'Opatch (11.2.0.3.5 = p6880880_112000_Linux-x86-64.zip).
cd $ORACLE_HOME
unzip /ora11ginst/OPatch/Patch\ 6880880/p6880880_112000_Linux-x86-64.zipet répondre « A » (« All »)
3. Décompresser le patch et lancer la vérification
unzip p17478514_112040_Linux-x86-64.zip
cd 17478514
opatch prereq CheckConflictAgainstOHWithDetail -ph ./4. Si la vérification répond « Prereq "checkConflictAgainstOHWithDetail" passed. », lancer la mise à jour
opatch apply« Entrée » sur « Adresse électronique/nom utilisateur : », et « O » sur « Voulez-vous ne pas être informé des problèmes de sécurité ([O]ui, [N]on) [N] ? »
Clone de la machine virtuelle RH7 (si nécessaire)
Stopper la VM, la cloner. Lancer la VM clonée, modifier l'adresse IP et /etc/hostname. Vérifier la souscription :
subscription-manager refreshEn cas de problème, la refaire :
subscription-manager clean
subscription-manager unregister
subscription-manager registerCréation des bases de données
Le programme Oracle ayant été installé seul (sans création de base), lancer d'abord "netca" pour créer un LISTENER, puis "dbca" pour créer les bases.
Suivre les écrans de création de la base (les options dépendent des besoins de la base, à voir individuellement).
Après création d'une base, si la console DBCONSOLE a été installée (par défaut), on y accède par :
https://176.100.3.145:1158/emL'initialisation de l'environnement Oracle en console se fait par :
. /usr/local/bin/oraenv
ou
. oraenv
si le PATH est correctDémarrage-arrêt automatique du listener et des bases :
- modifier /etc/oratab, mettre "Y" (en bout de ligne) pour les bases à lancer/arrêter automatiquement
- créer un fichier /etc/systemd/system/dboracle.service contenant :
[Unit]
Description=Oracle Autostart Service
After=syslog.target network.target
[Service]
Type=simple
RemainAfterExit=yes
User=oracle11
Group=oinstall
ExecStart=/u01/app/oracle/product/11.2.0/dbhome_1/bin/dbstart /u01/app/oracle/product/11.2.0/dbhome_1
ExecStop=/u01/app/oracle/product/11.2.0/dbhome_1/bin/dbshut /u01/app/oracle/product/11.2.0/dbhome_1
[Install]
WantedBy=multi-user.targetActiver le démarrage automatique des bases Oracle :
systemctl enable dboracle.serviceSi nécessaire, le démarrage manuel de bases est possible par :
$ORACLE_HOME/bin/dbstart $ORACLE_HOMEEt l'arrêt des bases:
$ORACLE_HOME/bin/dbshut $ORACLE_HOMERessources
http://docs.oracle.com/cd/E11882_01/install.112/e24326/toc.htm#BHCHBHDB
REBUILD de tous les indexes
Utiliser le code ci-dessous dans sqlplus pour lancer un REBUILD de tous les indexes :
set pages 1000
set lines 200
set echo off
set head off
set termout on
set trims on
set showmode off
set feed off
set verify off
column bname new_value dbname noprint
select name as bname from v$database;
ACCEPT OWN_INDX PROMPT "Nom du proprietaire des index : "
prompt
prompt ******** CREATION SCRIPT DE RECREATION DES INDEXES **************
spool REBUILD_INDEXES.sql
prompt spool REBUILD_INDEXES_&dbname..log
prompt set echo on
select 'alter index "'||trim(b.owner)||'"."'||trim(b.index_name)||'" rebuild;'
from dba_indexes b
where b.owner = '&OWN_INDX';
prompt spool off
spool off
prompt
prompt ****************** RECREATION DES INDEXES ********************************
set feed on
@REBUILD_INDEXES.sql
set echo off
prompt
prompt ** Les messages d'erreur sont visibles dans REBUILD_INDEXES_&dbname..log **
prompt
exitReconstruire la DBconsole sur Oracle 10g
Création/recréation de la console
Initialiser ORACLE_HOSTNAME avec le bon nom de serveur
Initialiser ORACLE_SID (mais peut-être pas nécessaire)
Lancer :
emca -config dbcontrol db -repos recreateEventuellement, pour être plus "propre", on peut la déconfigurer d'abord et la recréer ensuite
emca -deconfig dbcontrol db -repos drop
emca -config dbcontrol db -repos create(ça permet notamment de supprimer le répertoire de repo dans $ORACLE_HOME, avant recréation).
Répondre aux questions (SID, port listener, mots de passe des users ORACLE)
Cette opération ne fonctionne pas toujours du premier coup, il n'est pas rare d'avoir à la relancer 2, voire 3 fois, avant d'avoir le message magique :
La configuration d'Enterprise Manager a reussiEn cas d'erreur
à la création
SEVERE: Error creating the repositoryVérifier dans le log indiqué par le message. On doit trouver :
CONFIG: ORA-06502: PL/SQL: numeric or value error: character string buffer too small
ORA-06512: at line 259
oracle.sysman.assistants.util.sqlEngine.SQLFatalErrorException: ORA-06502: PL/SQL: numeric or value error: character string buffer too small
ORA-06512: at line 259
oracle.sysman.emcp.exception.EMConfigException: Error creating the repositoryVérifier tout d'abord que le ORACLE_HOME est bien positionné. Si oui, c'est un problème de longueur de variable dans le fichier sql de création de la console. Cette variable doit contenir le nom complet (FQDN) du host, et fait 32 caractères par défaut.
Pour vérifier si c'est le cas, se connecter SYSDBA :
SYS@ORCL> select host_name, length(host_name) length from v$instance;
HOST_NAME LENGTH
------------------------------------------------ -----------
hhhhhhhhhhhhhhhhh.dddddd.dddddddd 33
Elapsed: 00:00:00.09Solution :
echo $ORACLE_HOME
cd $ORACLE_HOME/sysman/admin/emdrep/sql/core/latest/self_monitor
cp self_monitor_post_creation.sql self_monitor_post_creation.sql_bkEditer self_monitor_post_creation.sql et remplacer
l_host_name VARCHAR2(32);par une taille pouvant contenir le nom du host (idéalement, 128).
NOTE: Il y a 2 définitions de cette variable à remplacer dans le fichier sql.
Sauvegarder le script et recréer la console.
à la suppression
ATTENTION : Le drop (donc le "recreate" aussi), met la base dans un état QUIESCE, empêchant de nouveau utilisateurs de se connecter. En cas de problème au moment de cette opération, la base peut rester dans cet état.
Pour la remettre dans un état normal :
SQL> select active_state from v$instance;
ACTIVE_ST
---------
QUIESCED
SQL> alter system unquiesce;
System altered.
SQL> select active_state from v$instance;
ACTIVE_ST
---------
NORMALRéduction/augmentation des REDO LOGs
Principe : on supprime et on recrée chaque REDO LOG à la bonne taille.
Trouver les nom des fichiers :
SQL> select * from v$logfile;Vérifier le statut courant :
SQL> select * from v$log;Note : on ne peut agir que sur des REDO "INACTIVE". Si le statut du REDO qu'on veut supprimer et recréer est "CURRENT" (en cours d'écriture) ou "ACTIVE" (il reste des transactions non fermées), basculer sur un autre REDO LOG :
SQL> alter system switch logfile;Si le REDO reste malgré tout "ACTIVE", forcer un checkpoint :
SQL> alter system checkpoint global;Suppression :
SQL alter database drop logfile group 2;Note : il doit toujours y avoir au moins deux groupes de REDO sur le système. Donc éventuellement, en créer un nouveau le temps d'agir sur un système à 2 REDO.
Recréation :
SQL> alter database add logfile group 2 '/u01/data/TEST/redo02.log' size 100M;Changement de taille des redos avec une standby (REDOs + Standby REDOs)
Procédure à suivre : Doc ID 1532566.1
Résumé :
- Retailler les redos + standby redos sur la primary
- Stopper le recover sur la standby
- Retailler les redos + standby redos sur la standby
- Relancer le recover sur la standby
Remplacement/resize d'un tablespace UNDO
Par exemple : le tablespace UNDO a grossi suite à de grosses modifications lancées sur la base. On veut le réduire.
Principe : il faut d'abord créer un second tablespace UNDO2 qu'on affectera par défaut à la base, puis modifier le DEFAULT de la base, puis refaire la manipulation inverse pour recréer UNDO.
SQL> CREATE UNDO TABLESPACE UNDO2
2 DATAFILE '/u02/oradata/TESTDB/undo2_01.dbf' SIZE 5M REUSE
3 AUTOEXTEND ON NEXT 1M MAXSIZE unlimited;
SQL> ALTER SYSTEM SET undo_tablespace=UNDO2;
SQL> DROP TABLESPACE UNDO INCLUDING CONTENTS AND DATAFILES;
SQL> CREATE UNDO TABLESPACE UNDO
2 DATAFILE '/u02/oradata/TESTDB/undo01.dbf' SIZE 500M REUSE
3 AUTOEXTEND ON NEXT 100M MAXSIZE unlimited;
SQL> ALTER SYSTEM SET undo_tablespace=UNDO;
SQL> DROP TABLESPACE UNDO2 INCLUDING CONTENTS AND DATAFILES;Note : Contrairement au tablespace TEMP où il suffit de suppimer les sessions qui l'utilisent, si des transactions (sessions) utilisent le UNDO, on doit attendre que les transactions passent en "EXPIRED".
select segment_name, sum(bytes/1024/1024) as "Taille (Mb)", status
from dba_undo_extents
where tablespace_name = 'UNDO'
and status in ('ACTIVE','UNEXPIRED')
group by segment_name,status
order by 2 desc;Remplacement/resize d'un tablespace TEMP
Par exemple : le tablespace TEMP a grossi suite à de grosses modifications lancées sur la base. On veut le réduire.
Principe : il faut d'abord créer un second tablespace TEMP2 qu'on affectera par défaut à la base, puis modifier le DEFAULT de la base, puis refaire la manipulation inverse pour recréer TEMP.
SQL> CREATE TEMPORARY TABLESPACE temp2
2 TEMPFILE '/u02/oradata/TESTDB/temp2_01.dbf' SIZE 5M REUSE
3 AUTOEXTEND ON NEXT 1M MAXSIZE unlimited;
SQL> ALTER DATABASE DEFAULT TEMPORARY TABLESPACE temp2;
SQL> DROP TABLESPACE temp INCLUDING CONTENTS AND DATAFILES;
SQL> CREATE TEMPORARY TABLESPACE temp
2 TEMPFILE '/u02/oradata/TESTDB/temp01.dbf' SIZE 500M REUSE
3 AUTOEXTEND ON NEXT 100M MAXSIZE unlimited;
SQL> ALTER DATABASE DEFAULT TEMPORARY TABLESPACE temp;
SQL> DROP TABLESPACE temp2 INCLUDING CONTENTS AND DATAFILES;Note : si le tablespace est utilisé par des sessions, on doit attendre la fin de leur traitement. En cas d'urgence, on peut aussi repérer les sessions qui l'utilisent, et les supprimer.
SELECT b.tablespace,b.segfile#,b.segblk#,b.blocks,a.sid,a.serial#,
a.username,a.osuser, a.status
FROM v$session a,v$sort_usage b
WHERE a.saddr = b.session_addr;
ALTER SYSTEM KILL SESSION '<SID>,<SERIAL#>' IMMEDIATE;RMAN - scripts standards
Quelques scripts pour l'utilisation standard de RMAN.
Configuration
# rman_conf
# This script configures RMAN. It needs to be run only once, but can be reloaded befor each backup.
CONFIGURE DEFAULT DEVICE TYPE TO DISK;
CONFIGURE RETENTION POLICY TO REDUNDANCY 2;
CONFIGURE DEVICE TYPE DISK PARALLELISM 2;
CONFIGURE CHANNEL DEVICE TYPE DISK FORMAT '/u01/orabackup/MYDB/%U';
#Autobackup control file to flash_recovery_area
CONFIGURE CONTROLFILE AUTOBACKUP ON;
#Autobackup control file to disk
#CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '/u01/orabackup/MYDB/ora_cf%F';
#If you want exlude a tablespace do this
#CONFIGURE EXCLUDE FOR TABLESPACE TBL_excludeBackup FULL
# rman_bck_full
# This script makes a FULL (level 0) backup
# Run it once a week
# The database must be in ARCHIVELOG mode to do a hot backup
BACKUP INCREMENTAL LEVEL 0 CUMULATIVE DEVICE TYPE DISK DATABASE;
BACKUP DEVICE TYPE DISK ARCHIVELOG ALL DELETE ALL INPUT;
BACKUP SPFILE;
ALLOCATE CHANNEL FOR MAINTENANCE TYPE DISK;
DELETE NOPROMPT OBSOLETE DEVICE TYPE DISK;
RELEASE CHANNEL;Backup incrémental
# rman_bck_incremental
# This script makes incremental CUMULATIVE backups. It is launched along the week, between two FULL backups.
# You need just the last FULL backup and the last CUMULATIVE backup to restore the database.
BACKUP INCREMENTAL LEVEL 1 CUMULATIVE DEVICE TYPE DISK DATABASE;
# BACKUP INCREMENTAL LEVEL 1 FOR RECOVER OF COPY WITH TAG 'mydb_incr_backup' DATABASE;
# The RECOVER COPY... line will not do anything until the script has been running for more than 7 days. The BACKUP INCREMENTAL line will perform image copy backups the first day it is run (and for any new datafiles), with all subsequent backups being level 1 incremental backups. After 7 days, the RECOVER COPY... line will start to take effect, merging all incremental backups older than 7 days into the level 0 backup, effectively moving the level 0 backup forward. The effect of this is that you will permanently have a 7 day recovery window with a 7 day old level 0 backup and 6 level 1 incremental backups. Notice that the tag must be used to identify which incremental backups apply to which image copies.
BACKUP DEVICE TYPE DISK ARCHIVELOG ALL DELETE ALL INPUT;Backup des archives uniquement
# rman_bck_arch
# This script makes an ARCHIVELOG backup and cleanup. It is launched multiple times a day
BACKUP DEVICE TYPE DISK ARCHIVELOG ALL DELETE ALL INPUT;Validation des backups
# rman_valid_restore
Run this script when you want to control that RMAN can restore database with existing backups
RESTORE DATABASE VALIDATE;
#RESTORE TABLESPACE read_only_tablespace_name VALIDATE;Restore et recovery
# rman_restore_recovery
#Do a full database recovery
#we need all configuration files :
#spfile, tnsnames.ora, and listener.ora at right location
#With NOCATALOG mode backup en mode, you MUST backup the DBID. To do this :
#with RMAN : RMAN target /
# RMAN>connected to target database: INVENTORY (DBID=1670954628)
#or: sqlplus "/ as sysdba"
# SQL>select dbid, name from v$database;
# Launch RMAN without "target /", only "rman" or "rman @<path>/<to>/script.rman"
# For using SET UNTIL option, the database backup file BEFORE the "set until" time (and the archivelog backup files) must be present in the backup directory.
#Put the DBID on the following line :
SET DBID <database_id>;
CONNECT TARGET /;
STARTUP NOMOUNT;
LIST BACKUP;
LIST BACKUP SUMMARY;
CROSSCHECK BACKUP;
# CATALOG START WITH '/safe/oracle/@/backup/'
RUN
{
SET CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '/safe/oracle/@/backup/ora_cf%F';
RESTORE CONTROLFILE FROM '/RAID0/orasauve/@/nom_backup_controlfile';
# Mount database BEFORE set until
ALTER DATABASE MOUNT;
# NOTE : "SET" only available in a RUN block
# SET UNTIL TIME 'SYSDATE-3';
# SET UNTIL TIME “to_date(‘04-07-2008 00:30:00′, ‘DD-MM-YYYY HH24:MI:SS’)”;
RESTORE DATABASE;
RECOVER DATABASE;
ALTER DATABASE OPEN RESETLOGS;
}
# NOTE : RESETLOGS force a new incarnation of the database
# Erreurs possibles :
# ERROR : RMAN-06004: ORACLE error from recovery catalog database: RMAN-20207: UNTIL TIME or RECOVERY WINDOW is before RESETLOGS
# Cause: UNTIL TIME and RECOVERY WINDOW cannot be less than the database creation time or RESETLOGS time.
# Action: Check the UNTIL TIME or RECOVERY WINDOW. If the database needs to be restored to an old incarnation, use the RESET DATABASE TO INCARNATION command.
# (RMAN> list incarnation;)
# difficile de remonter la dernière sauvegarde de base après avoir fait un essai de restore until. Le restore incomplet et le resetlogs sont enregistrés, une nouvelle incarnation de la base a été générée, un autobackup a été fait et une archive a peut-être été créée depuis... Le mieux pour les tests est de faire une sauvegarde COLD complète de la base avant les tests.
#if an ORA-01152 error occurs, do that :
#SQL> recover database until cancel using backup controlfile;
#SQL> Alter database open resetlogs;Maintenance courante
# rman_maintenance
# It check for obsolete backups (see REDUDANCY parameter) and delete them
CROSSCHECK BACKUP OF DATABASE;
#REPORT NEED BACKUP;
DELETE OBSOLETE;
# To delete a specific backup do this :
#LIST BACKUP;
#DELETE BACKUPPIECE numero_BP;
# Print all existing backups
#LIST BACKUP SUMMARY;Simuler "SU" sous sqlplus
Exemple pratique : un DBlink ne peut être créé/supprimé que par l'utilisateur propriétaire, même pas par SYS.
Si on a pas le mot de passe de l'utilisateur, on peut simuler un "SU" :
connecté SYS AS SYSDBA sous SQLPLUS :
Suppression d'un dblink DBL appartenant à USER1
declare
uid number;
sqltext varchar2(100) := 'DROP DATABASE LINK DBL';
myint integer;
begin
select user_id into uid from all_users where username like 'USER1';
myint:=sys.dbms_sys_sql.open_cursor();
sys.dbms_sys_sql.parse_as_user(myint,sqltext,dbms_sql.native,uid);
sys.dbms_sys_sql.close_cursor(myint);
end ;
/Création d'un dblink DBL appartenant à USER1
declare
uid number;
sqltext varchar2(100) := 'CREATE DATABASE LINK DBL CONNECT TO USERREMOTE IDENTIFIED BY PASSWORDREMOTE USING ''DBREMOTETNS''';
myint integer;
begin
select user_id into uid from all_users where username like 'USER1';
myint:=sys.dbms_sys_sql.open_cursor();
sys.dbms_sys_sql.parse_as_user(myint,sqltext,dbms_sql.native,uid);
sys.dbms_sys_sql.close_cursor(myint);
end ;
/Suppression de JOB Oracle 10g
JOB lancé par une application
Trouver l'identifiant du JOB (job=identifiant, what=contenu):
select job,substr(what,1,20),next_date from dba_jobs;Est-il bien RUNNING ? (oui s'il apparait dans la table suivante) :
select job,last_date from dba_jobs_running;Tenter de le supprimer :
EXEC DBMS_JOB.REMOVE(<numéro du job>);Si ça ne suffit pas, trouver la session qui a lancé le job :
SELECT job,s.sid,s.serial#,spid FROM dba_jobs_running d, v$session s, v$process p WHERE d.sid = s.SID AND s.PADDR = p.ADDR;Les colonnes intéressantes sont SID et SERIAL#
Tuer la session correspondante :
alter system kill session '<sid>,<serial#>';en reprenant les valeurs trouvés dans la requête précédente.
JOB planifié dans Oracle
NOTE : PROCEDURE A TESTER.
On peut tenter :
BEGIN
dbms_scheduler.drop_job( <job name> [,<force>] );
END;Ou force est un booléen, à FALSE par défaut, qu'on peut mettre à TRUE.
Supprimer tous les objets d'un utilisateur en une seule fois
Supprimer tous les objets d'un utilisateur
set serveroutput on
declare
u VARCHAR(5) := 'ADM';
begin
DBMS_OUTPUT.ENABLE( 1000000 ) ;
-- Les tables sont a part car la syntaxe du drop est differente
for x in (select table_name from dba_tables where owner=u)
loop
dbms_output.put_line ('Dropping TABLE '||x.table_name);
execute immediate 'drop table '||u||'.'||x.table_name||' cascade constraints';
end loop;
for x in (select object_name,object_type from dba_objects where owner=u and object_type not in ('LOB','PACKAGE BODY') and object_name not like 'BIN$%')
loop
dbms_output.put_line ('Dropping '||x.object_type||' '||x.object_name);
execute immediate 'drop '||x.object_type||' '||u||'.'||x.object_name;
end loop;
end;On peut reprendre ce principe et forcer l'exécution de DDL (exemple : ajout de droits, modification de structure en masse, etc..) multiple par ce genre de code :
begin
for x in (select table_name from dba_tables where owner='ADM')
loop
execute immediate 'GRANT SELECT ON ' || x.table_name || ' TO USER_RO';
end loop;
end;Trace SQL sur session utilisateur
Oracle : Activer une trace SQL sur une session
Repérer le sid et serial# de la session :
col username format A10
col osuser format A20
col machine format A20
select sid, serial#, username, osuser, machine from v$session;Activer la trace :
EXECUTE DBMS_MONITOR.SESSION_TRACE_ENABLE(<sid>,<serial#>,TRUE,TRUE);Les fichiers sont générés dans udump.
Arrêter la trace :
EXECUTE DBMS_MONITOR.SESSION_TRACE_DISABLE(<sid>,<serial#>);Les fichiers ne sont pas très lisibles. On a intérêt à les passer "à la moulinette" :
tkprof <nom_du_fichier.trc> <fichier_de_sortie.txt>
Trouver ce qui charge le CPU
Repérer avec "top" le process ID qui charge le CPU. Puis dans sqlplus :
select a.sid, a.serial#, a.program, b.sql_text
from v$session a, v$sqltext b
where a.sql_hash_value = b.hash_value
and a.sid=xxxxx
order by a.sid,hash_value,piece;où "xxxxx" est l'ID du processus repéré dans "top".
On pourra ensuite, en dernier recours, tuer la session avec les sid et serial# trouvés ci-dessus
alter system kill session '<sid>, <serial#>';Trouver les requêtes longues
Dans sqlplus :
col SQL_FULLTEXT format A60
SELECT * FROM
(SELECT
sql_fulltext,
sql_id,
elapsed_time,
child_number,
disk_reads,
executions,
first_load_time,
last_load_time
FROM v$sql
ORDER BY elapsed_time DESC)
WHERE ROWNUM < 10puis :
SELECT * FROM table (DBMS_XPLAN.DISPLAY_CURSOR('&sql_id', &child));Upgrade manuel (version <= 11.2.0)
Peut être réalisé sur le même serveur en upgradant les binaires Oracle (bases arrêtées), mais dans ce cas il faut que la (les) base(s) ai(en)t été sauvegardée(s) avant !
Alternative : copier tous les fichiers d'une base (arrêtée) de version X vers une nouvelle base (vide) crée dans une version X+1. Les chemins doivent être rigoureusement identiques entre les 2 bases (donc forcément sur 2 serveurs différents).
On peut utiliser l'assistant graphique DBUA si disponible.
Modifier les chemins ORACLE_BASE, ORACLE_HOME pour pointer sur la nouvelle version. Puis :
sqlplus / AS SYSDBA
SQL> STARTUP UPGRADE
SQL> SPOOL UPGRADE.LOG
SQL> @?/rdbms/admin/catupgrd.sql
Après redémarrage de la base en mode normal, recompiler d'éventuels objets en erreur :
SQL> @?/rdbms/admin/utlrp.sqlUpgrade mineur Oracle 11g
Arrêter la (les) base(s) sur le serveur et mettre à jour les binaires d'Oracle (suivre les documentations fournies avec la nouvelle version).
Lancer la base en mode UPGRADE et mettre le système à jour
sqlplus / AS SYSDBA
SQL> STARTUP UPGRADE
SQL> SPOOL UPGRADE.LOG
SQL> @?/rdbms/admin/catupgrd.sql
SQL> @?/rdbms/admin/utlrp.sql
SQL> shutdown immediate;
SQL> startup;[EDIT] A partir de la version 12c (12.2), utiliser plutôt le script dbupgrade en ligne de commande.
Utilisation de EXPLAIN PLAN
EXPLAIN PLAN n'éxecute pas la requête, il ne fait que la calculer. Il n'y a donc pas de risque de charge même sur une base en production.
Dans sqlplus :
SQL> EXPLAIN PLAN FOR
2 select prod_category, avg(amount_sold)
3 from sales s, products p
4 where p.prod_id = s.prod_id
5 group by prod_category;
Explained.SQL> select plan_table_output
2 from table(dbms_xplan.display('plan_table',null,'basic'));
------------------------------------------
Id Operation Name
------------------------------------------
0 SELECT STATEMENT
1 HASH GROUP BY
2 HASH JOIN
3 TABLE ACCESS FULL PRODUCTS
4 PARTITION RANGE ALL
5 TABLE ACCESS FULL SALES
------------------------------------------Vider automatiquement la corbeille RECYCLE_BIN
Le script SQL suivant active la corbeille de tables supprimées (RECYCLE_BIN), et crée respectivement :
- une table de log des vidages de la corbeille
- une procédure qui purge la corbeille avec une rétention définie
- un programme qui lance la procédure avec la rétention en argument
- un job qui lance le programme selon une fréquence définie
-- Tips : how to disable RECYCLEBIN, delete JOB and PROGRAM
-- Execute this script as SYSTEM
-- Note : need to close and restart session
-- ALTER SYSTEM SET recyclebin = OFF DEFERRED;
-- BEGIN
-- DBMS_SCHEDULER.DISABLE ('PERIODIC_PURGE_RECYCLE_BIN_JOB');
-- END;
-- /
-- BEGIN
-- DBMS_SCHEDULER.drop_job (job_name => 'PERIODIC_PURGE_RECYCLE_BIN_JOB');
-- END;
-- /
-- BEGIN
-- DBMS_SCHEDULER.DISABLE ('PERIODIC_PURGE_RECYCLE_BIN');
-- END;
-- /
-- BEGIN
-- DBMS_SCHEDULER.drop_program (program_name => 'PERIODIC_PURGE_RECYCLE_BIN');
-- END;
-- /
-- Enable recycle bin
ALTER SYSTEM SET recyclebin = ON DEFERRED;
-- Create JOB_LOG table if not exists
DECLARE
table_exist number;
BEGIN
select count(table_name) into table_exist from dba_tables
where table_name='JOB_LOG';
IF table_exist = 0 THEN
EXECUTE IMMEDIATE 'CREATE TABLE SYSTEM.job_log (
ts TIMESTAMP DEFAULT SYSTIMESTAMP,
message VARCHAR2(255))';
END IF;
END;
/
-- For verification
-- SELECT OWNER, TABLE_NAME FROM DBA_TABLES WHERE TABLE_NAME = 'JOB_LOG';
-- Create procedure PURGE_RECYCLE_BIN
CREATE OR REPLACE PROCEDURE SYSTEM.PURGE_RECYCLE_BIN (v_nbjours IN INT) AUTHID CURRENT_USER AS
TYPE cur_typ IS REF CURSOR;
c cur_typ;
v_cur_sql VARCHAR(200);
v_owner VARCHAR(200);
v_oname VARCHAR(200);
v_sql VARCHAR(200);
BEGIN
v_cur_sql := 'SELECT owner, original_name FROM sys.dba_recyclebin WHERE droptime < to_char(sysdate-'||v_nbjours||',''YYYY-MM-DD:HH24:MI:SS'') AND type=''TABLE''';
OPEN c FOR v_cur_sql;
LOOP
FETCH c INTO v_owner, v_oname;
EXIT WHEN c%NOTFOUND;
v_sql := 'PURGE TABLE '||v_owner||'.'||v_oname;
EXECUTE IMMEDIATE v_sql;
-- for debugging:
-- dbms_output.put_line('Table '||v_oname||' purged from RECYCLEBIN.');
INSERT INTO job_log(message) VALUES ('Table '||v_oname||' purged from RECYCLEBIN.');
END LOOP;
CLOSE c;
END;
/
-- For verification
-- SELECT OWNER,PROCEDURE_NAME FROM DBA_PROCEDURES WHERE PROCEDURE_NAME LIKE '%RECYCLE%';
-- Create program+argument (default : v_nbjours=180)
BEGIN
DBMS_SCHEDULER.CREATE_PROGRAM(
PROGRAM_NAME => 'PERIODIC_PURGE_RECYCLE_BIN',
PROGRAM_TYPE => 'STORED_PROCEDURE',
PROGRAM_ACTION => 'SYSTEM.PURGE_RECYCLE_BIN',
NUMBER_OF_ARGUMENTS => 1,
ENABLED => FALSE,
COMMENTS => 'PERIODIC_PURGE_RECYCLE_BIN'
);
END;
/
BEGIN
DBMS_SCHEDULER.DEFINE_PROGRAM_ARGUMENT(
PROGRAM_NAME => 'PERIODIC_PURGE_RECYCLE_BIN',
argument_name => 'V_NBJOURS',
argument_position => 1,
argument_type => 'INT',
default_value => '180'
);
END;
/
BEGIN
DBMS_SCHEDULER.ENABLE ('PERIODIC_PURGE_RECYCLE_BIN');
END;
/
-- For verification
-- SELECT PROGRAM_NAME,ENABLED FROM DBA_SCHEDULER_PROGRAMS WHERE PROGRAM_NAME LIKE '%RECYCLE%';
-- Schedule and activate job with program
BEGIN
DBMS_SCHEDULER.CREATE_JOB (
job_name => 'PERIODIC_PURGE_RECYCLE_BIN_JOB',
start_date => to_date('01/10/20 23:00:00', 'DD/MM/YY HH24:MI:SS'),
end_date => NULL,
repeat_interval => 'FREQ=DAILY',
PROGRAM_NAME => 'PERIODIC_PURGE_RECYCLE_BIN',
ENABLED => FALSE,
COMMENTS => 'PERIODIC_PURGE_RECYCLE_BIN_JOB'
);
END;
/
BEGIN
DBMS_SCHEDULER.SET_JOB_ARGUMENT_VALUE (
job_name => 'PERIODIC_PURGE_RECYCLE_BIN_JOB',
argument_name => 'V_NBJOURS',
argument_value => 1
);
END;
/
BEGIN
DBMS_SCHEDULER.ENABLE ('PERIODIC_PURGE_RECYCLE_BIN_JOB');
END;
/
-- For verification
-- SELECT JOB_NAME,PROGRAM_NAME,NUMBER_OF_ARGUMENTS,NEXT_RUN_DATE,ENABLED FROM DBA_SCHEDULER_JOBS WHERE JOB_NAME LIKE '%RECYCLE%';
EXITVoir les requêtes courantes, longues, les conflits, les verrous
Voir les requêtes en cours :
SET LINESIZE 20000
SELECT nvl(ses.username,'ORACLE PROC')||' ('||ses.sid||')' USERNAME,
SID,
MACHINE,
REPLACE(SQL.SQL_TEXT,CHR(10),'') STMT,
ltrim(to_char(floor(SES.LAST_CALL_ET/3600), '09')) || ':'
|| ltrim(to_char(floor(mod(SES.LAST_CALL_ET, 3600)/60), '09')) || ':'
|| ltrim(to_char(mod(SES.LAST_CALL_ET, 60), '09')) RUNT
FROM V$SESSION SES,
V$SQLtext_with_newlines SQL
where SES.STATUS = 'ACTIVE'
and SES.USERNAME is not null
and SES.SQL_ADDRESS = SQL.ADDRESS
and SES.SQL_HASH_VALUE = SQL.HASH_VALUE
and Ses.AUDSID <> userenv('SESSIONID')
order by runt desc, 1,sql.piece;ou
SET LINESIZE 20000
select x.sid
,x.serial#
,x.username
,x.sql_id
,x.sql_child_number
,optimizer_mode
,hash_value
,address
,sql_text
from v$sqlarea sqlarea
,v$session x
where x.sql_hash_value = sqlarea.hash_value
and x.sql_address = sqlarea.address
and x.username is not null;
Voir les conflits :
prompt CTIME is in Seconds
set linesize 120
col BLOCK format 9
col LMODE format 9
col INST_ID format 9
col REQUEST format 9
col SID format 999999
SELECT INST_ID,
SID,
TYPE,
ID1,
ID2,
LMODE,
REQUEST,
CTIME,
BLOCK
FROM
GV$LOCK
WHERE
(ID1,ID2,TYPE) IN
(SELECT ID1, ID2, TYPE FROM GV$LOCK WHERE request>0);Voir les verrous :
SET LINESIZE 20000
select
object_name,
object_type,
session_id,
type, -- Type or system/user lock
lmode, -- lock mode in which session holds lock
request,
block,
ctime -- Time since current mode was granted
from
v$locked_object, all_objects, v$lock
where
v$locked_object.object_id = all_objects.object_id AND
v$lock.id1 = all_objects.object_id AND
v$lock.sid = v$locked_object.session_id
order by
session_id, ctime desc, object_name;
Voir les opération longues :
COLUMN percent FORMAT 999.99
SELECT sid, to_char(start_time,'hh24:mi:ss') stime,
message,( sofar/totalwork)* 100 percent
FROM v$session_longops
WHERE sofar/totalwork < 1;Voir les requêtes > 15 minutes :
column username format 'a10'
column osuser format 'a10'
column module format 'a16'
column program_name format 'a20'
column program format 'a20'
column machine format 'a20'
column action format 'a20'
column sid format '9999'
column serial# format '99999'
column spid format '99999'
set linesize 200
set pagesize 30
select
a.sid,a.serial#,a.username,a.osuser,c.start_time,
b.spid,a.status,a.machine,
a.action,a.module,a.program
from
v$session a, v$process b, v$transaction c,
v$sqlarea s
Where
a.paddr = b.addr
and a.saddr = c.ses_addr
and a.sql_address = s.address (+)
and to_date(c.start_time,'mm/dd/yy hh24:mi:ss') <= sysdate - (15/1440) -- running for > 15 minutes
order by c.start_time;
select sid, serial#,SQL_ADDRESS, status,PREV_SQL_ADDR from v$session where sid='xxxx' //(enter the sid value)
select sql_text from v$sqltext where address='XXXXXXXX';
ou :
select SQL_TEXT from v$sqlarea where address='XXXXXXXX';Mise à jour avec nettoyage des patchs
Depuis avril 2023 (patch 37), on peut supprimer les anciennes versions mineures (patchs) d'Oracle pour récupérer de la place (des Gos !) avant mise à jour.
Il semble (à valider) que ça fonctionne aussi bien pour Grid (Restart) que pour Database.
Les informations ici :
https://oracle-base.com/articles/misc/clean-up-the-patch-storage-directory
ou ici :